


爬取论坛标题与链接存入 excel
爬取后,方便大家直接在 excel 中找到已分享的经验的标题与对应的链接。
代码如下:
import requests, xlwt
from bs4 import BeautifulSoup
from lxml import etree
url_list = [] # 用于存放标题和url
# 获取源码
def get_content(url):
html = requests.get(url).content
return html
# 获取某页中的所有帖子的url
def get_url(html):
soup = BeautifulSoup(html, 'lxml') # lxml是解析方式,第三方库
blog_url_list = soup.find_all('h2', class_='fn-ellipsis')
for i in blog_url_list:
url_list.append([i.find('a').text, i.find('a')['href']])
# print(url_list)
last_list.append(url_list)
start_url = 'http://support.i-search.com.cn/recent?p=1'
response = requests.get(start_url)
content = response.text
selector = etree.HTML(content)
maxPage = selector.xpath('//*[@class="pagination"]/a[10]/text()')[0].replace(">>","")
print(maxPage)
for page in range(1, int(maxPage)):
url = 'http://support.i-search.com.cn/recent?p={}'.format(page)
get_url(get_content(url))
newTable = '//mac/Home/Desktop/isearch_list2.xls'
wb = xlwt.Workbook(encoding='utf-8') # 打开一个对象
ws = wb.add_sheet('blog') # 添加一个sheet
headData = ['标题', '链接']
# 写标题
for colnum in range(0, 2):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font:bold on')) # 第0行的第colnum列写入数据headDtata[colnum],就是表头,加粗
index = 1
lens = len(url_list)
# 写内容
for j in range(0, lens):
ws.write(index, 0, url_list[j][0])
ws.write(index, 1, url_list[j][1])
index += 1 # 下一行
wb.save(newTable) # 保存
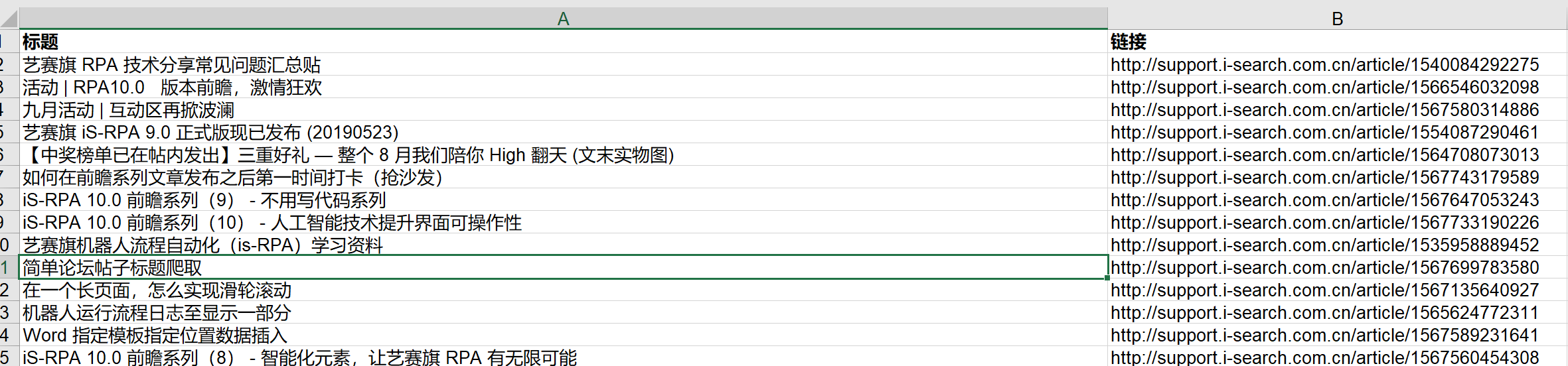
实现结果如下图所示:

这个可以有
这个必须点赞👍
这个可以有,我需要正好查看网站哪些 URL 没有被收率
有一个疑问 你写的这个遵循 ROBOTS 文件的规定吗?
不会的呢 😄
你们是想把社区给爬兀了么 😆
不错不错