
wangwei


机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
其他经验 机器学习 数据分析 RPA • 5 回帖 • 3.5K 浏览 • 2019-08-27 17:18:34
机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
其他经验 机器学习 数据分析 RPA • 5 回帖 • 3.5K 浏览 • 2019-08-27 17:18:34
电影评论数据分析 + RPA 机器学习 5 终篇 - (哪吒之魔童降世 - 词向量聚类、舆情分析 )
电影 < 哪吒之魔童降世 > 评论数据分析 + RPA 机器学习 - 电影评论数据分析

需求库

配置风格
数据读取

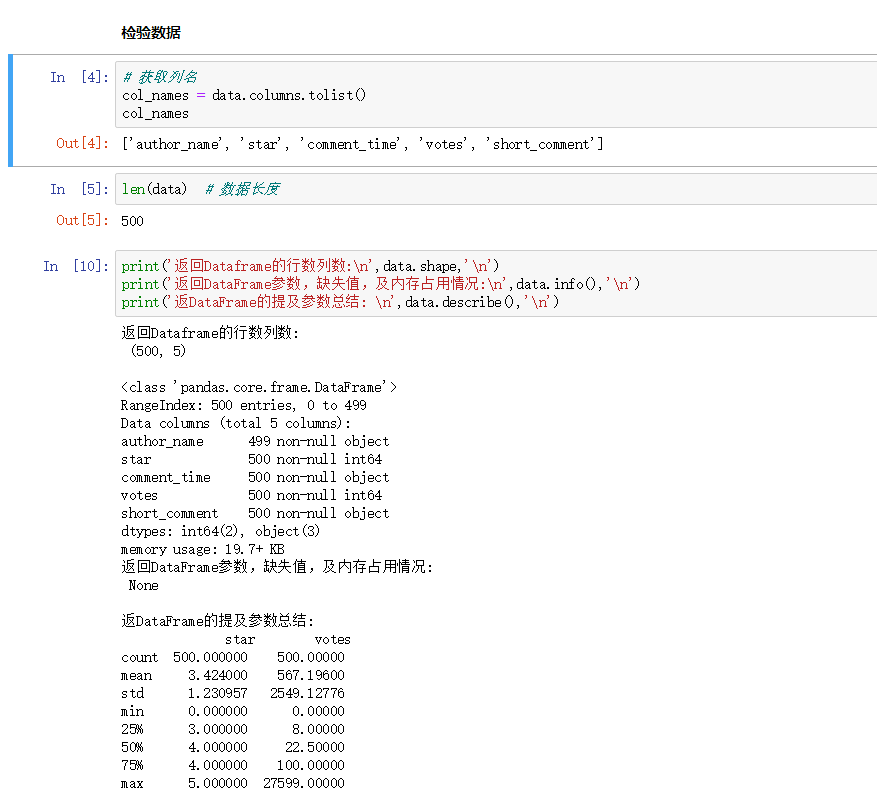
检验数据
1、数据分析
1.1 平均分

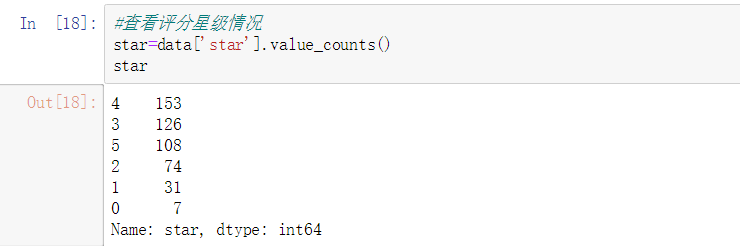
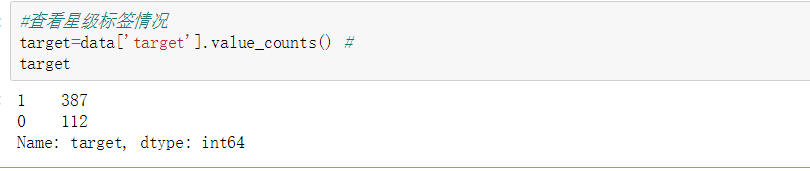
1.2 查看评分星级情况
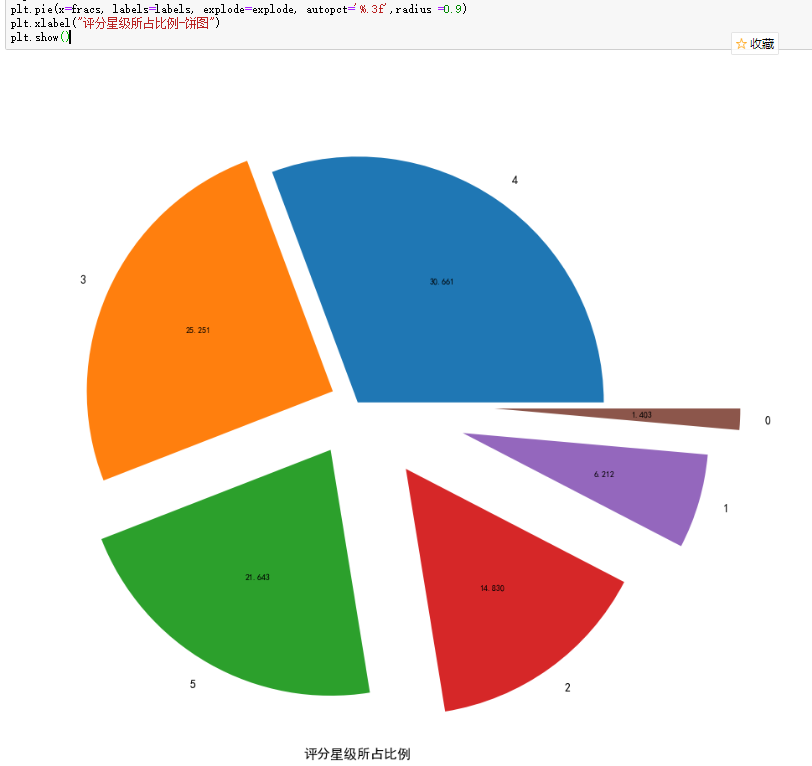
1.3 评分星级所占比例 饼图
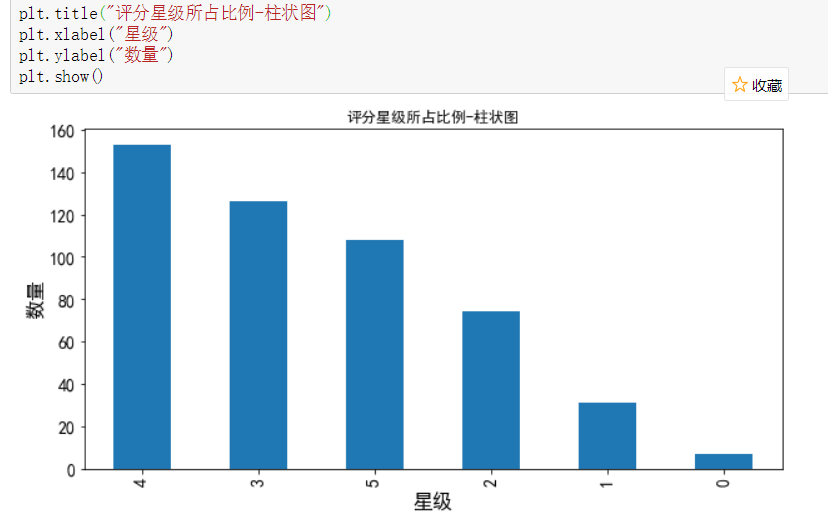
1.4 评分星级所占比例 - 柱状图
2、分词 和 词云可视化
2.1、通过星级转换标签,这里只取两个,即 3 星级前后
#特征值转换
data['target'] = data['star'].map(lambda x:zhuanhuan(x))
data_model = data.dropna()
2.2 不使用停用词进行 词云可视化和词频统计
词云展示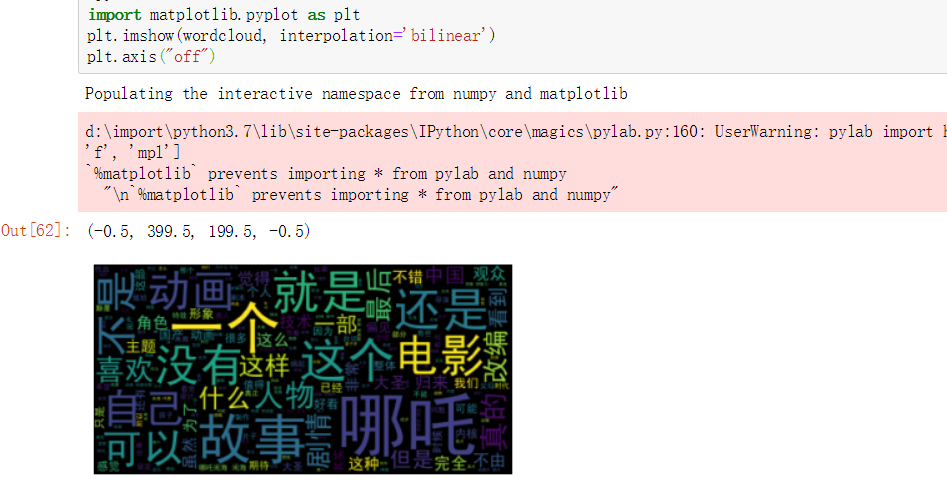
词频统计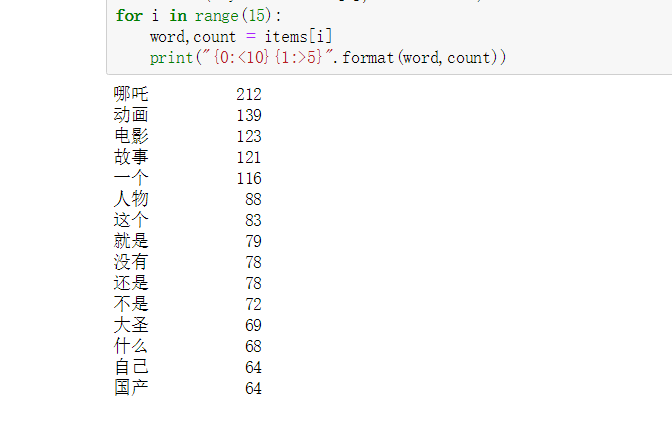
2.3 用停用词进行 词云可视化和词频统计
读取停用词
词云展示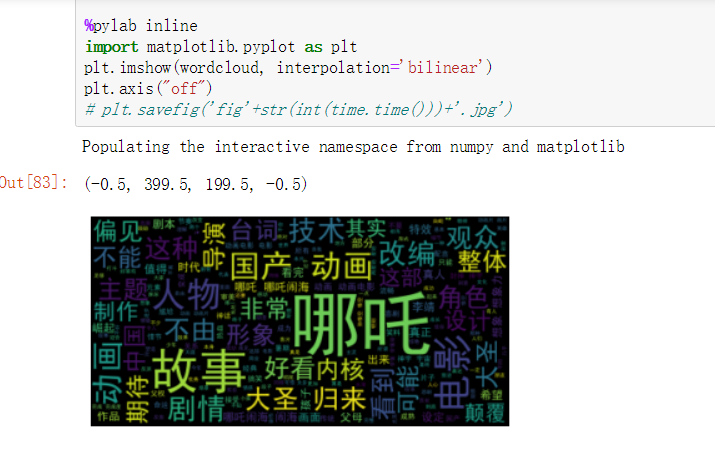
自定义词云样式 词云展示
词频统计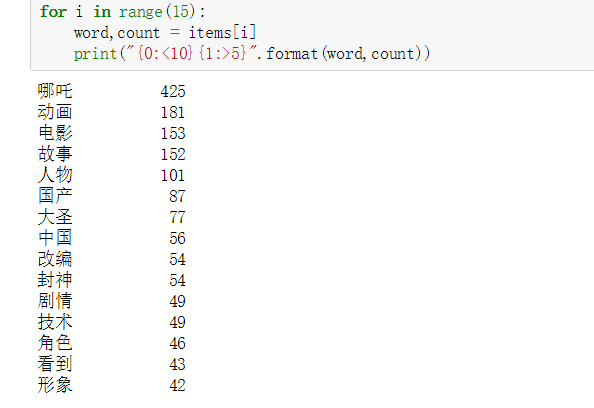
3、词向量训练聚类(机器学习)
3.1 提取短评内容,存放至 txt

3.2 写日志文件、训练文本中的词做处理
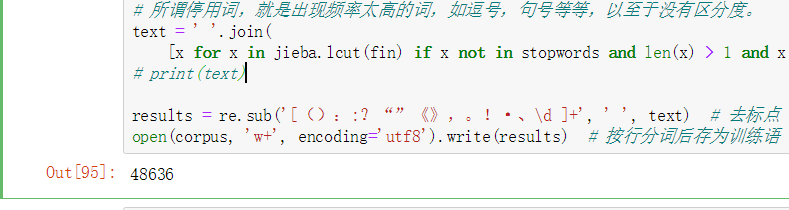
3.3 训练模型(训练一次就可以了,有保存的训练结果)
sentences = word2vec.LineSentence(corpus) # 加载语料,LineSentence用于处理分行分词语料
# sentences1 = word2vec.Text8Corpus(corpus) #用来处理按文本分词语料
3.4、保存模型,以便重用
model.save("test_01.model") # 保存模型
3.5、加载模型,验证模型
预测相似性 similarity
聚类
# 计算某个词的相关词列表
figures = ['哪吒', '大圣', '动画', '国产', '李靖','东海','敖丙']
结果
> 和[哪吒]最相关的词有:
扒皮 0.9512418508529663
以为 0.9271668195724487
说明 0.9235397577285767
意思 0.9233090877532959
抽筋 0.9229607582092285
恶童 0.9202382564544678
魔珠 0.9181482195854187
身后 0.9179489612579346
原有 0.9178143739700317
原罪 0.917594850063324
> 和[大圣]最相关的词有:
归来 0.9383881092071533
功夫 0.9287267923355103
缺点 0.9204697012901306
超越 0.9197591543197632
情绪 0.9153766632080078
国风 0.9053506255149841
态度 0.9051592350006104
鼓励 0.9017831087112427
刻画 0.8933018445968628
结合 0.880815863609314
> 和[动画]最相关的词有:
达到 0.9259344935417175
编剧 0.9236827492713928
江山 0.9178018569946289
当成 0.9148873686790466
实名 0.9130635261535645
吐槽 0.9103395938873291
可见一斑0.9097391366958618
垃圾 0.9091787338256836
建模 0.9091485142707825
不靠 0.9089758396148682
> 和[国产]最相关的词有:
扎实 0.9579017162322998
仍然 0.953188419342041
可见一斑0.9490149021148682
却是 0.9486746788024902
达到 0.9407460689544678
很棒 0.9359941482543945
炸裂 0.9334836006164551
D 0.9320415258407593
宿命论 0.9318063259124756
层面 0.9313121438026428
> 和[李靖]最相关的词有:
揭穿 0.9492337703704834
阉割 0.9303153157234192
整个 0.9286620020866394
有力 0.9227673411369324
三太子 0.9213778376579285
抽筋 0.9190459251403809
原著 0.9179681539535522
夫妻 0.9151644706726074
身份 0.9144698977470398
面前 0.9143165349960327
> 和[东海]最相关的词有:
矛盾 0.964309573173523
爸爸 0.9575396776199341
国外 0.9550043344497681
宝宝 0.9515457153320312
古代 0.9512234926223755
小组 0.9507986307144165
典范 0.9484009742736816
背影 0.9475916624069214
最低 0.9437093734741211
略显 0.943335771560669
> 和[敖丙]最相关的词有:
太极 0.9614375829696655
浓重 0.9595965147018433
倒错 0.9544601440429688
人心 0.9542381763458252
阴阳 0.9480985403060913
一体 0.9273303151130676
哲学 0.9235407114028931
二元 0.9215266704559326
太乙 0.9214966297149658
全部 0.9210331439971924
4、情感分析
X 是全部特征。因为只用文本判断情感,所以 X 实际上只有 1 列
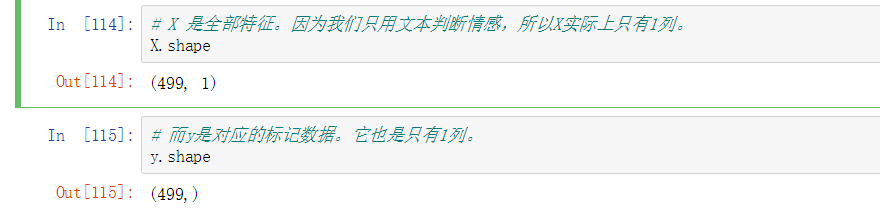
而 y 是对应的标记数据。它也是只有 1 列

建立一个辅助函数,把结巴分词的结果用空格连接。

使用这个函数,用 apply 命令,把每一行的评论数据都进行分词
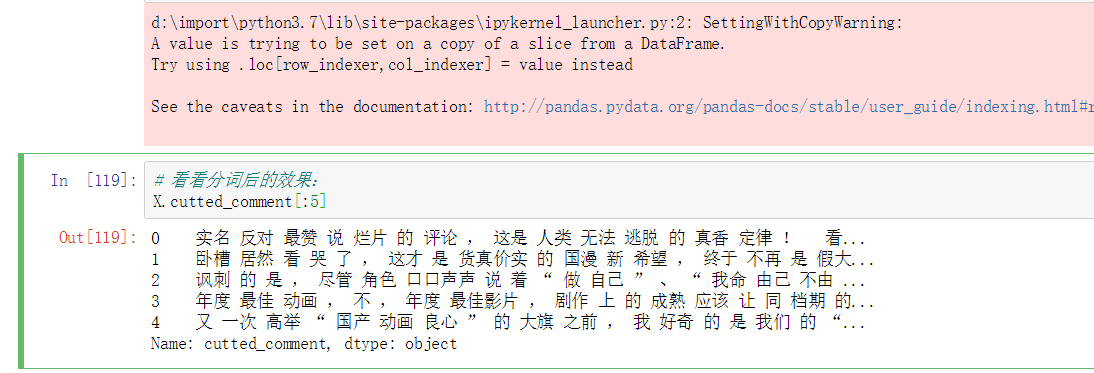
机器学习—- 把数据分成训练集和测试集
4.1 把数据集拆开,只在训练集上训练。保留测试集先,作为参考,看模型经过训练后的分类效果
此时的 X_train 数据集形状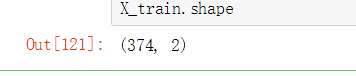



4.2 对分词后的中文语句做向量化
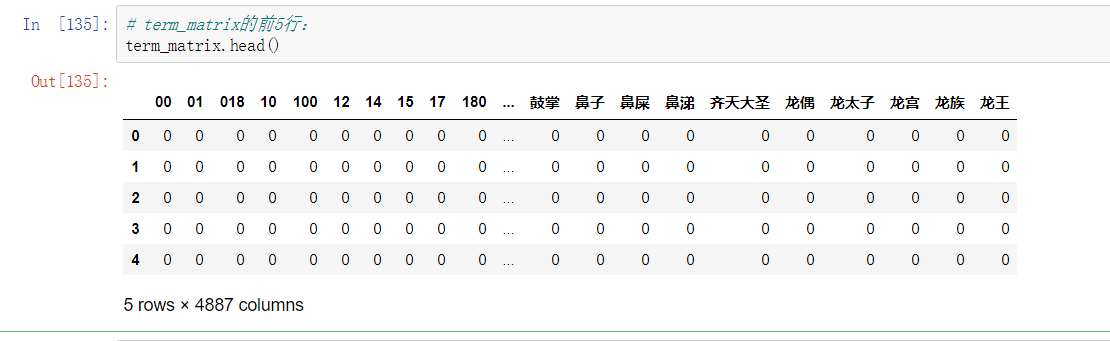

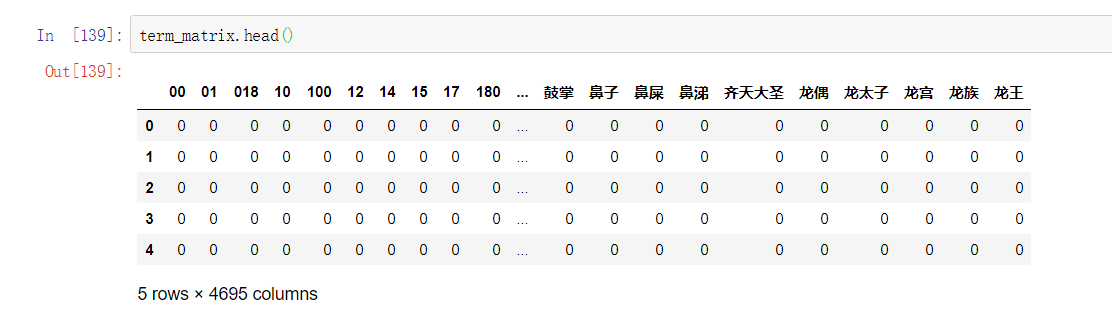

可以看到,此时特征个数减少了。没有调整任何其他的参数,因此减少的 192 个特征,就是出现在停用词表中的单词
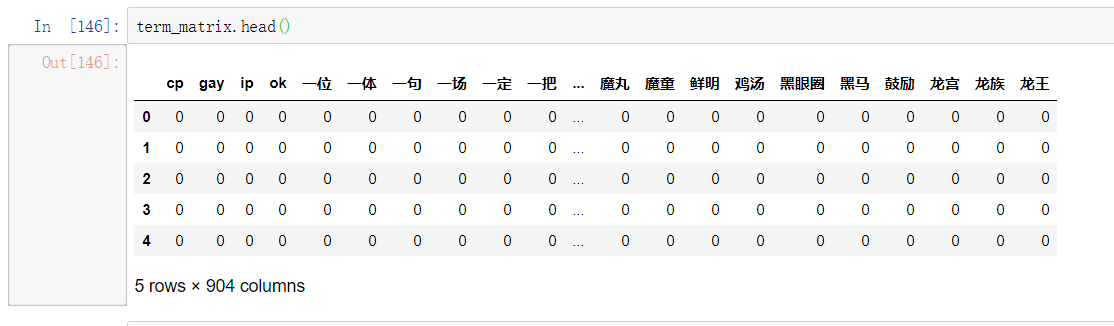

可以看到,那些数字全都不见了。特征数量从单一词表法去除停用词之后,变成了 904 个
把未经特征向量化的训练集内容输入,做交叉验证,算出模型分类准确率的均值。
from sklearn.model_selection import cross_val_score
cross_val_score(pipe, X_train.cutted_comment, y_train, cv=5, scoring='accuracy').mean()
结果

在测试集上,对情感分类标记进行预测
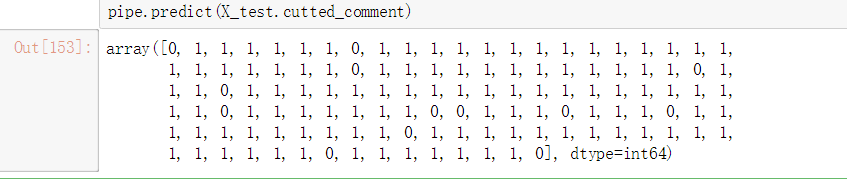
通过 scikit-learn 的测量工具集 看看测试准确率

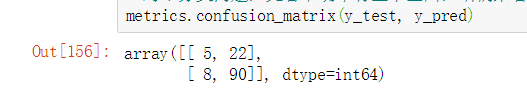
查看 混淆矩阵的结果

结果 和 SnowNLP 作对比
from snownlp import SnowNLP # python情感分析库
def get_sentiment(text):
return SnowNLP(text).sentiments



对比的结果,是 TP 和 TN 两项上,模型判断正确数量,都要超出 SnowNLP。
5、情感分析 之后的数据分析
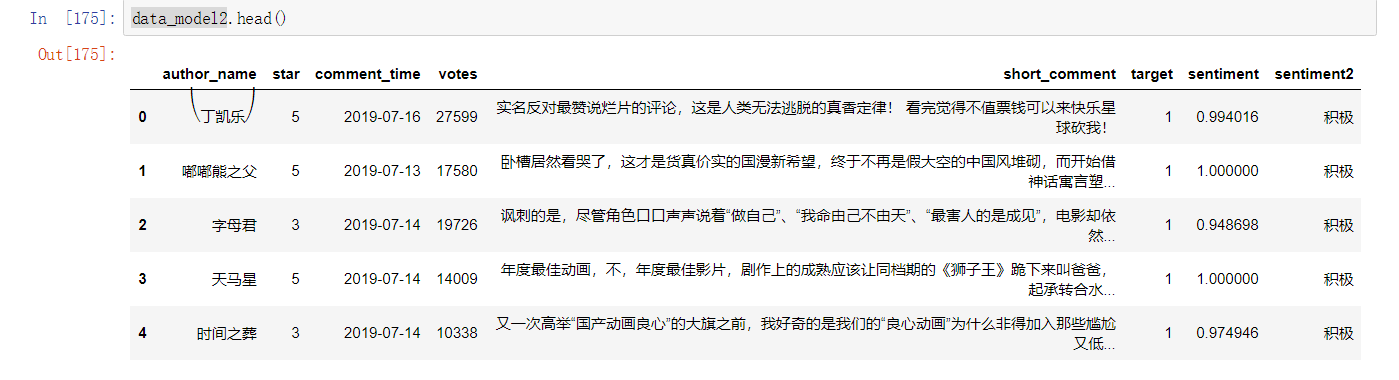
积极消极的所有信息
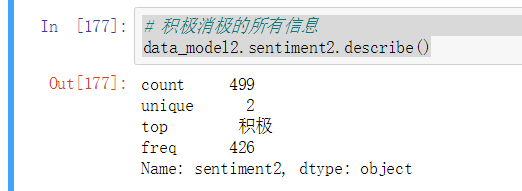
积极消极的所有信息 柱状图
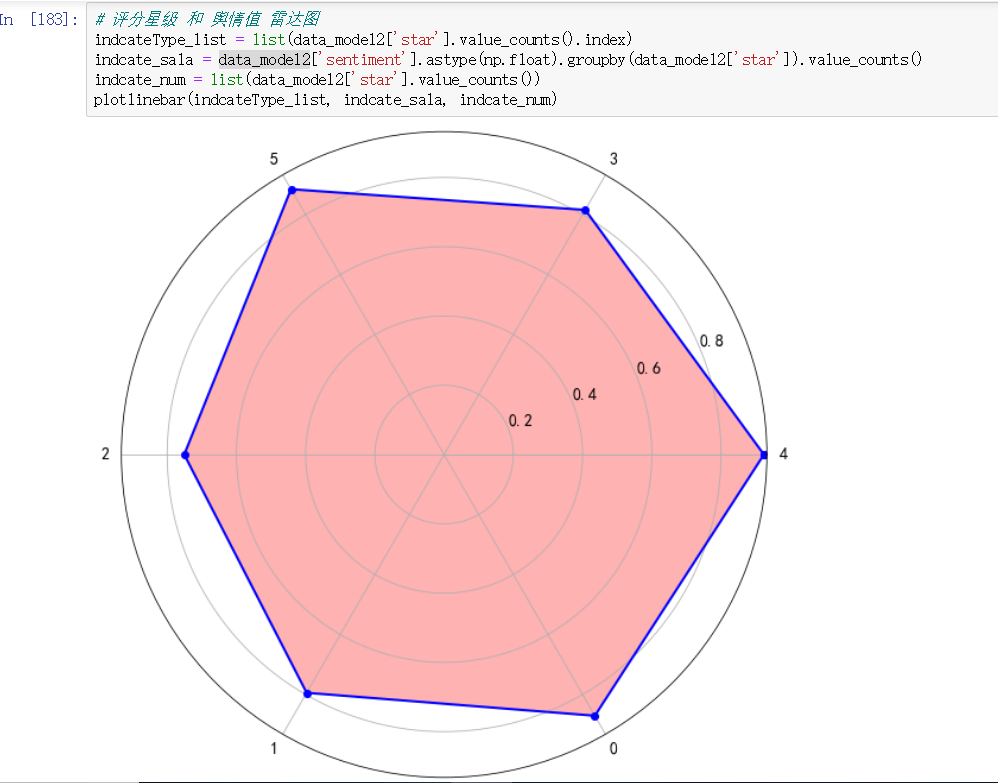
按评分星级求平均值

评分星级 和 舆情值 雷达图
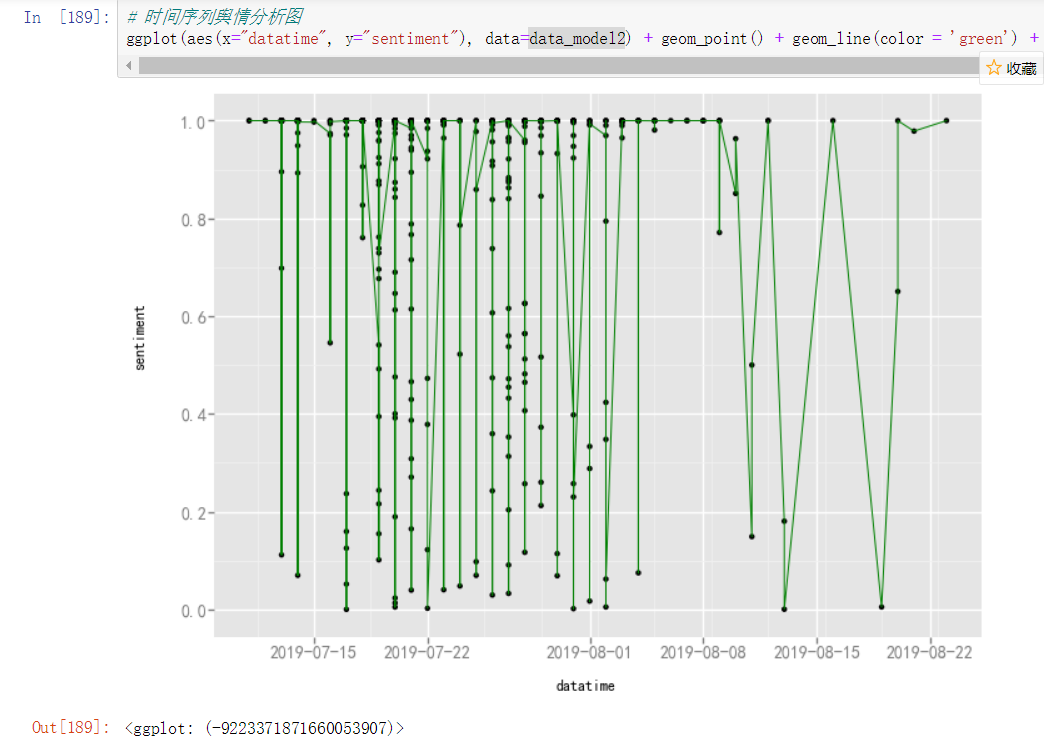
时间序列舆情分析图
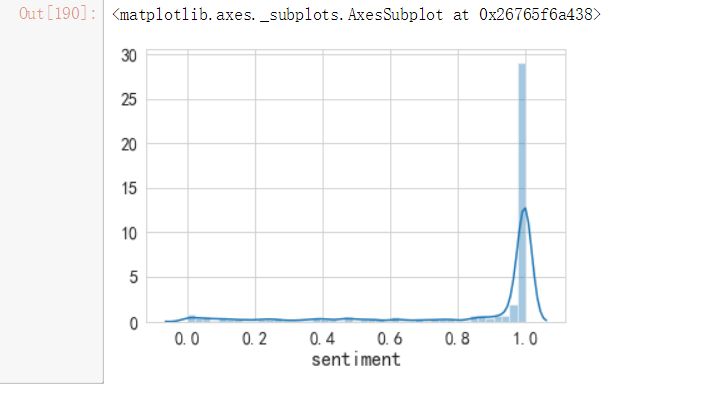
舆情目标变量分布
至此。
哪吒之魔童降世 的 评分数据分析 和 评论数据分析 全部结束了。
代码,都在 github 上面了。

你好 github 上没有找到源码,能给下源码吗
回帖内容已被屏蔽。
牛皮
学习
哇塞,好东西。必须收藏 😆