


【计时方法】五、使用 cProfile 模块(上)
cProfile 是一个标准库内建的分析工具。它钩入 CPython 的虚拟机来测量其每一个函数运行所花费的时间。这一技术会引入一个巨大的开销,但你会获得更多的信息。有时这些额外的信息会给你的代码带来令人惊讶的发现。
分析工作的一个好的实践是在开始分析之前先对代码各部分的运行速度进行假设。提前生成一个假设意味着有可能测出你错的有多离谱(而且真的会测出!)并提升你对于某种编程风格的直觉。
警告: 永远不要忽视靠直觉进行的性能分析(虽然你一定会犯错!)。在分析前先进行假设是绝对值得的,因为这样可以帮助你学习如何定位你代码中可能有问题的地方,而且你应该始终用证据来证明你的选择。
这里,我们用 cProfile 模块运行我们之前提到的找到最大或最小的 N 个元素文末所设计的最小堆:
import heapq
class TopK:
def __init__(self, iter_obj, k):
self.minheap = []
self.maxsize = k
self.iter_obj = iter_obj
def push(self, item):
if len(self.minheap) >= self.maxsize:
min_item = self.minheap[0]
if item > min_item:
heapq.heapreplace(self.minheap, item)
else:
heapq.heappush(self.minheap, item)
def get_topk(self):
for item in self.iter_obj:
self.push(item)
return self.minheap
if __name__ == '__main__':
print(sorted(TopK(range(100000001), 100).get_topk()))
我们将这个文件命名为 topk.py,在命令行中切换到该文件所在的目录下后,我们运行如下代码:python -m cProfile -s cumulative topk.py
其中 -s cumulative 开关告诉 cProfile 对每个函数累计花费的时间进行排序,这能让我们看到代码最慢的部分。cProfile 会将输出直接打印到屏幕: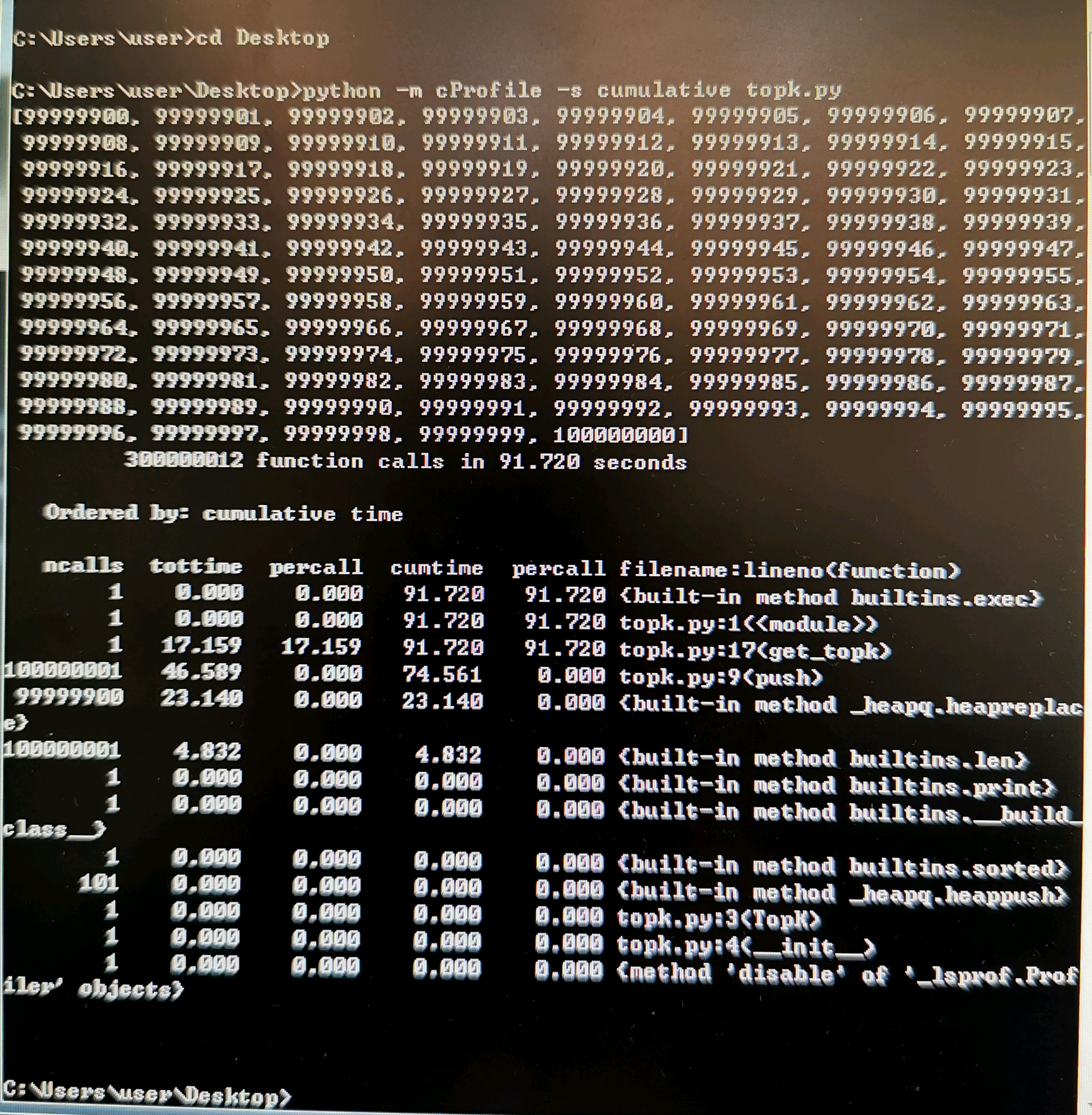
对累计时间排序能告诉我们大部分的执行时间花在了哪。这个结果显示出在 91.72 秒的时间里一共发生了 300000012 次函数调用(这个时间包括了使用 cProfile 的开销)。
我们可以看到第二行,topk.py 的代码入口点总共花费了 91.72 秒。这是通过 __main__ 调用来实现的。ncalls 为 1,意味着这行仅执行了一次。
在类 TopK 内部,get_topk() 方法的调用花费了 91.72 秒,而花在(那些没有调用其他函数的)代码行上的时间是 17.159 秒。该函数调用了 100000001 次 push,总共花了 74.561 秒。
另外,我们可以发现一共执行了 99999900 次 heapreplace 操作,用时 23.14 秒。以及 101 次 heappush 操作,用时可以忽略不计。
push 除去必要的操作后,花在逻辑判断等操作上的时间为 46.589 秒,约占 push 操作的 62.5%,从中我们可以推断出 push 的内部逻辑一定有可以优化的地方。
性能分析输出的最后一行提到了 lsprof,这是本工具进化到 cProfile 之前的原始名字,可以忽略。
为了获得对 cProfile 结果的更多控制,我们可以生成一个统计文件然后通过 Python 进行分析,在命令行中输入:python -m cProfile -o profile.stats topk.py
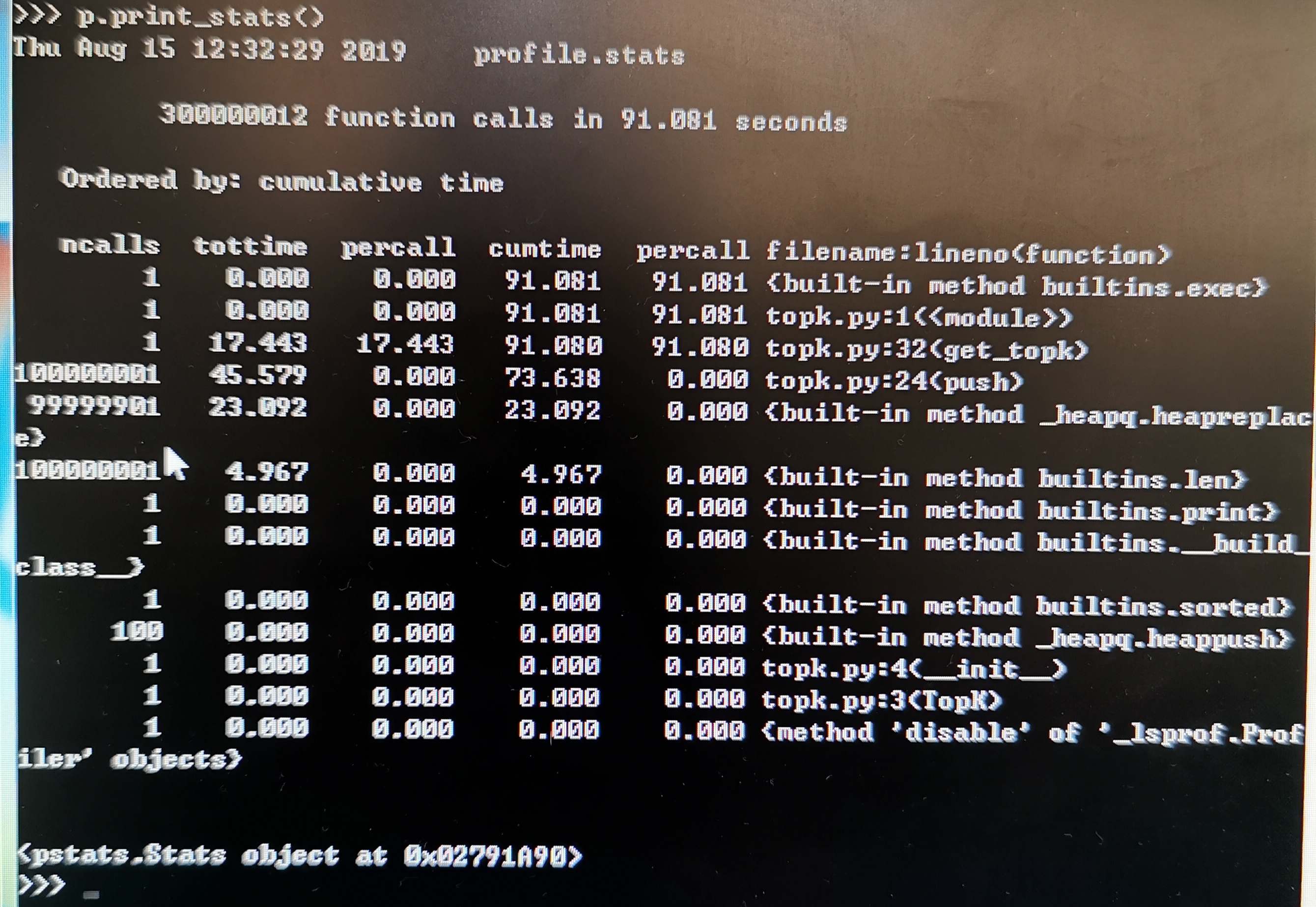
然后就会在当前文件夹下生成一个 profile.stats 文件,我们可以这样将其调入 Python,它会输出跟之前一样的累计时间报告:
>>> import pstats
>>> p = pstats.Stats("profile.stats")
>>> p.sort_stats("cumulative")
<pstats.Stats instance at 0x02791A90>
>>> p.print_stats()
为了追溯我们分析的函数,我们可以打印调用者的信息。在下面的图片中,我们可以看到 get_topk 中的 push 操作是最耗时的函数: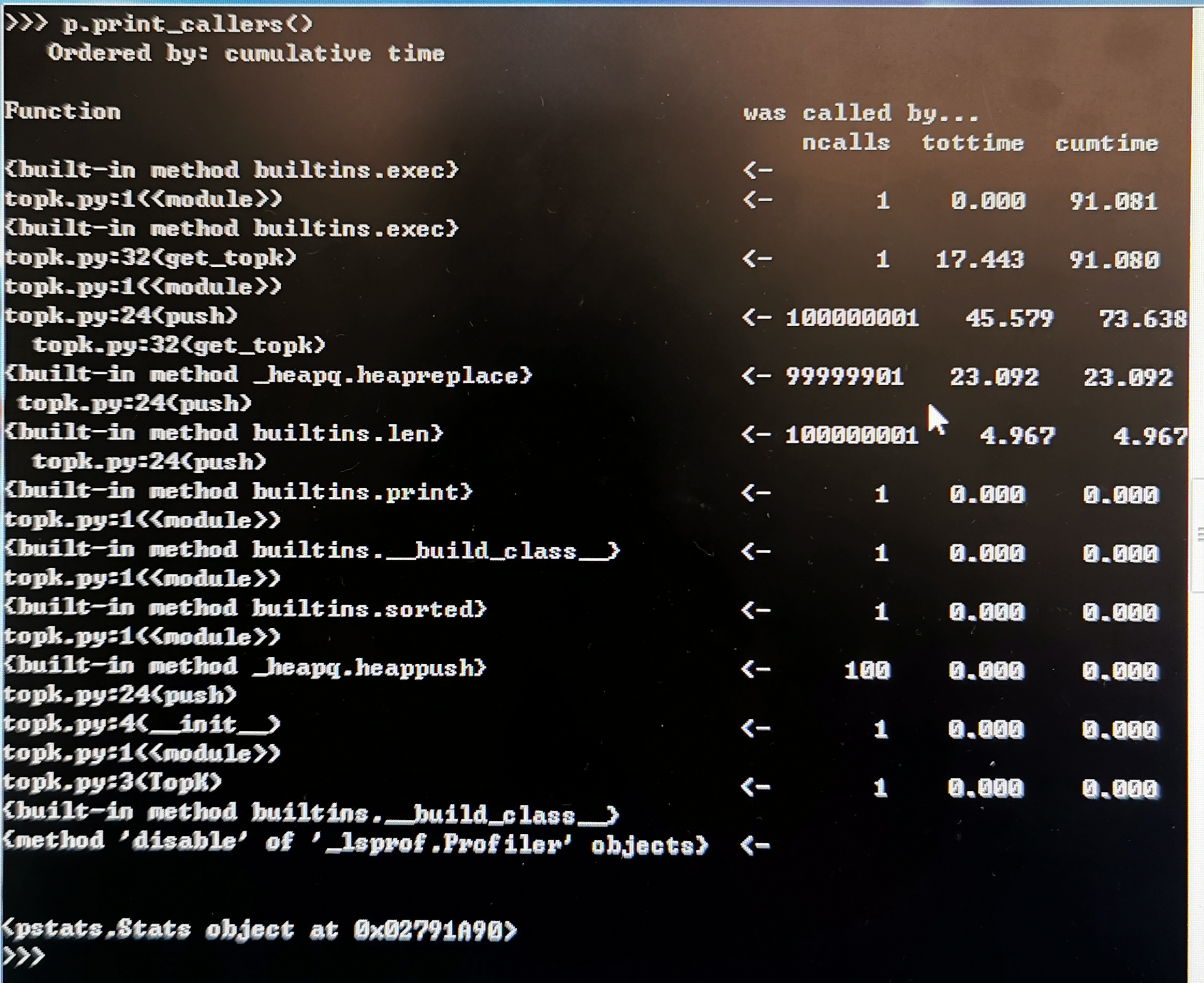
我们还可以反过来显示哪个函数调用了其他函数: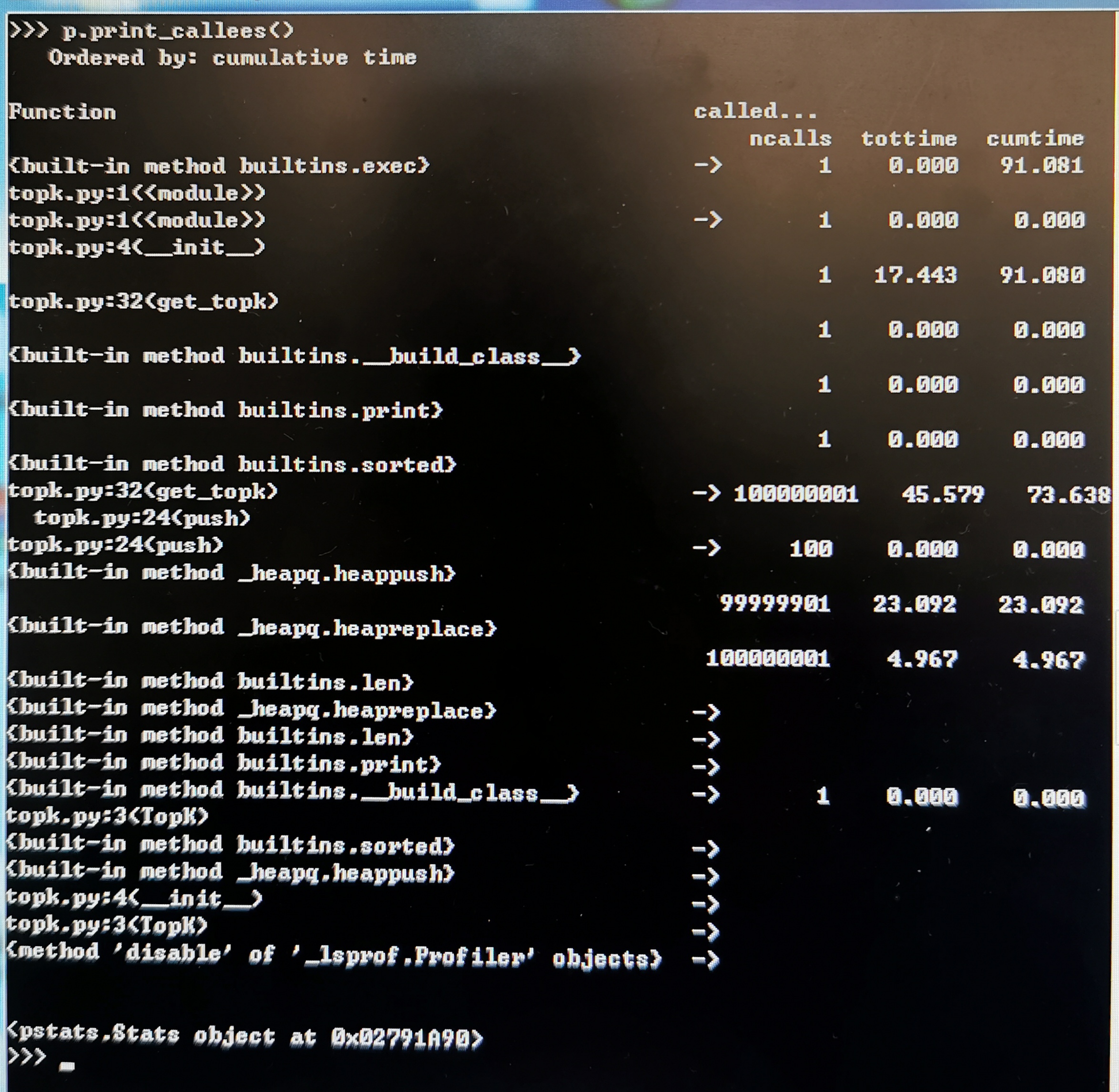

study~