使用 urllib 模块通过 url 进行文件下载
import urllib.request
#下载链接
down_url=r"https://av.sc.com/hk/zh/content/docs/hk-c-nddr-ff304m-ag-20190809.pdf"
#储存路径
down_path=r"C:\Users\Administrator\Desktop\selenium\aa.pdf"
#链接转码,防止链接中有中文而报错
#safe:为无需转码的字符
down_url = urllib.parse.quote(down_url, safe=":/=?#")
#执行下载
urllib.request.urlretrieve(down_url,down_path)
若使用的过程中报错:urllib.error.HTTPError: HTTP Error 403: Forbidden
则将请求头添加到进请求中,代码如下:
import urllib.request
#下载链接
down_url=r"https://av.sc.com/hk/zh/content/docs/hk-c-nddr-ff304m-ag-20190809.pdf"
#储存路径
down_path=r"C:\Users\Administrator\Desktop\selenium\aa.pdf"
#链接转码,防止链接中有中文而报错
#safe:为无需转码的字符
down_url = urllib.parse.quote(down_url, safe=":/=?#")
#模拟请求头
opener = urllib.request.build_opener()
opener.addheaders=[('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36')]
urllib.request.install_opener(opener)
#执行下载
urllib.request.urlretrieve(down_url,down_path)
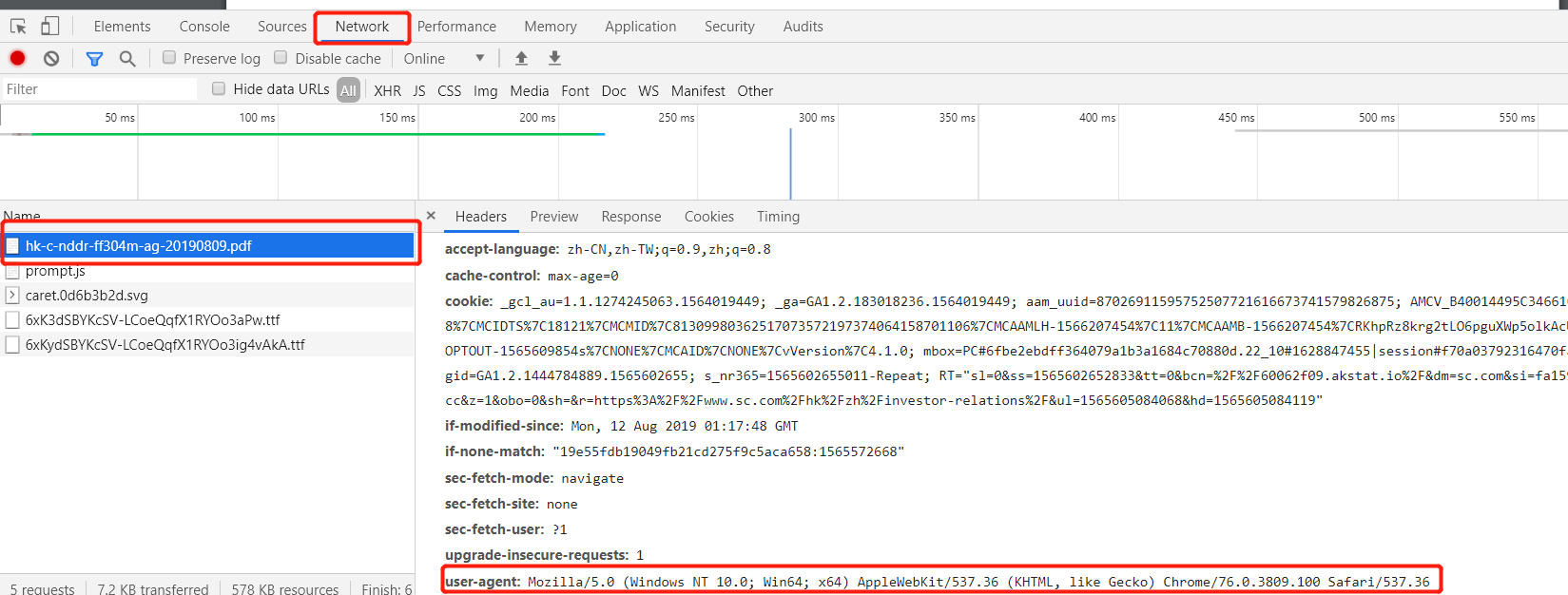
请求头 headers 获取:
打开浏览器 按 F12 找到 Network 模块