


爬虫信息获取测试 shell
解决需求点:
1.poc 过程经常遇到一些网页内容,此时利用设计器获取文本的方式效率不是很高,使用爬虫的情况下效率会变高。
此时,通过 xpath 解析网页结构拾取信息是比较快捷的操作方式。而 scrapy 框架的 shell 终端是测试拾取成功与否
的更加快捷方式。
2. 以拾取论坛首页帖子标题为例:
>>> scrapy shell http://support.i-search.com.cn/

>>> response
>>>response.xpath("//div[@class='module']//h2/a/text()").extract()
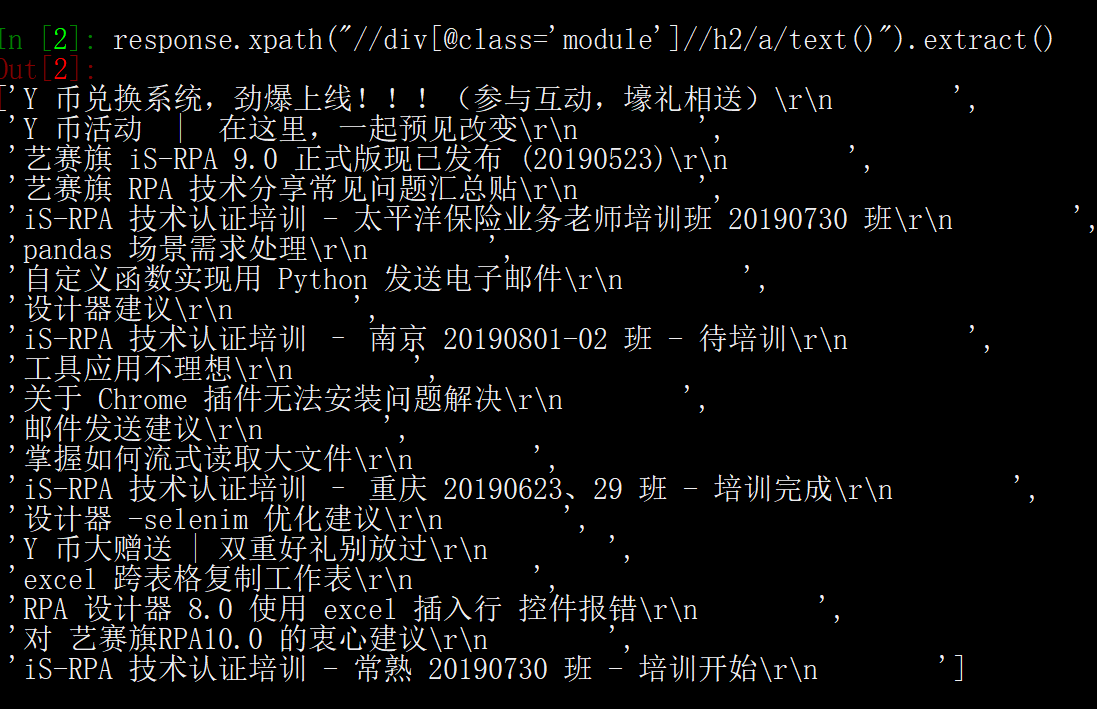
通过以上简单方法,就可以直观的观察到爬虫结果获取情况,从而方便 poc 难点的继续进行。

是的,爬虫使用广度比较大。
爬虫用好了还是挺方便的 👍