
网页上判断单选按钮和复选框值的简单方法
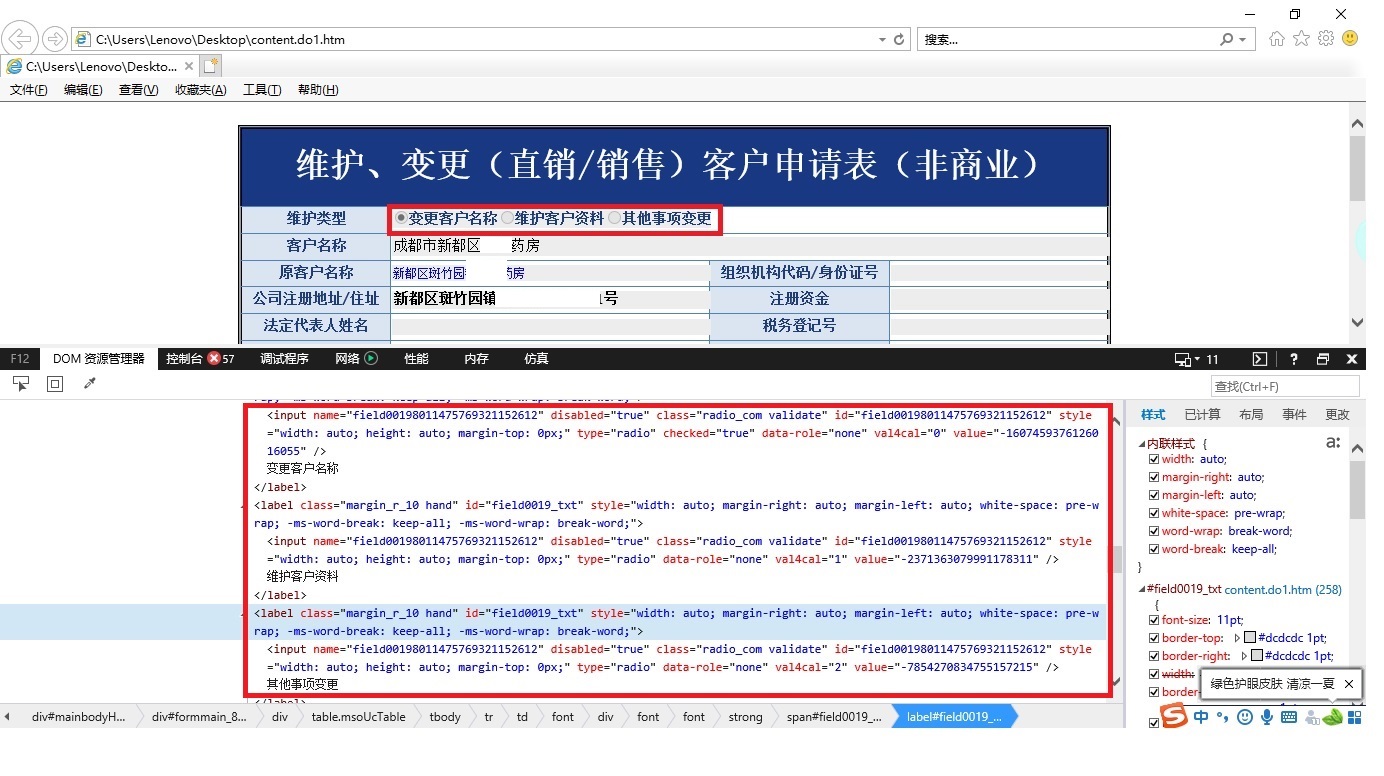
代理商 POC 问题一:
不知道如何用 RPA 去获取如上图 维护类型 中单选按钮的值。
解决办法:
1. 通过 css selector [:checked] 去找到单选按钮的值,三个单选按钮的 value 值是固定不变的。
2. 通过预先定义的字典遍历比较,得到维护类型的值。
字典:{‘-1607459376126016055’:‘变更客户名称’,‘-2371363079991178311’:‘维护客户资料’,‘-7854270834755157215’:‘其他事项变更’}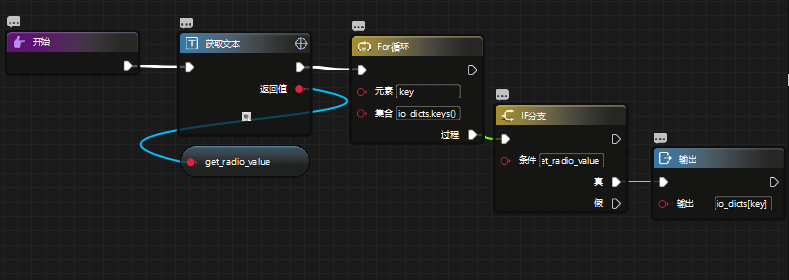
😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊 😊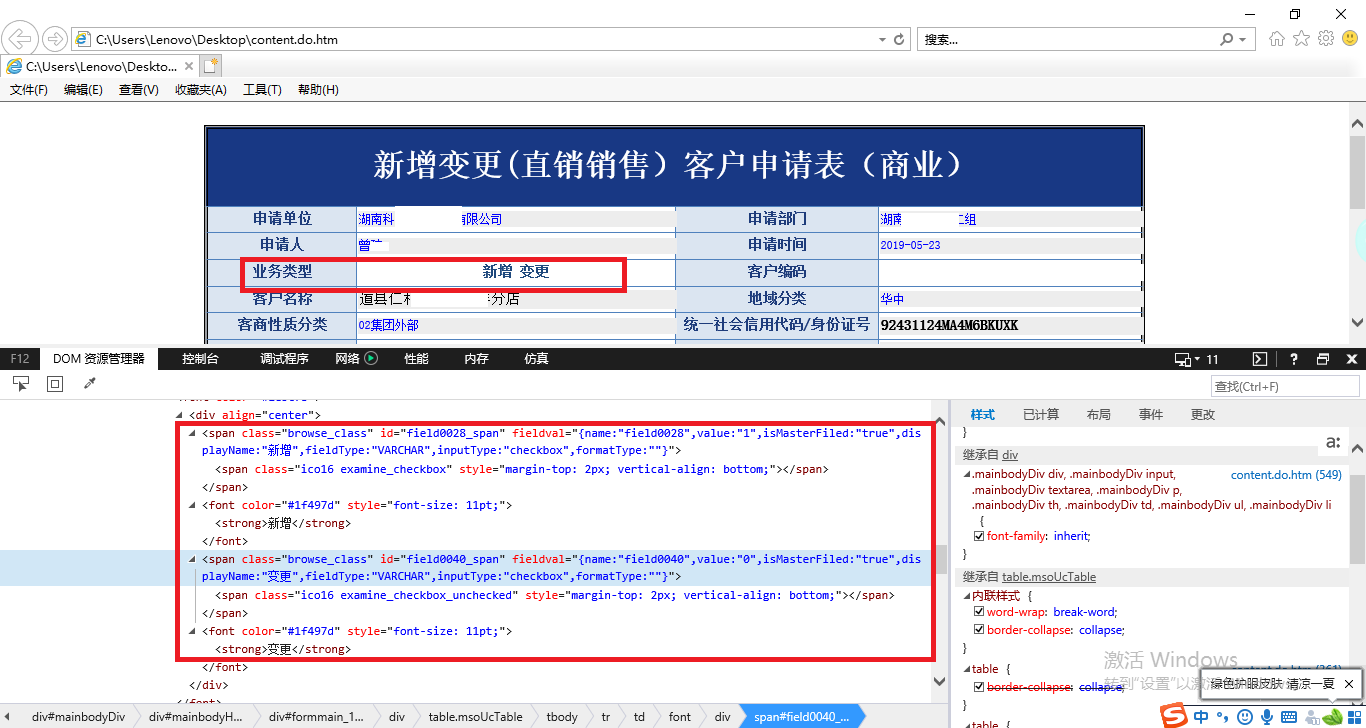
代理商 POC 问题二:
不知道如何获取到业务类型的值。
解决办法:
1. 尝试通过自定义写 css selector ,尝试失败(不知道你是否知道如何写?),用 xpath 应该可以实现。
2. 通过元素的属性获取数据进行判断,使用 select() 来寻找所有 id 为 field0028_span 和 field0040_span 的元素,然后将第一个分别匹配到 spanElem_field0028 和 spanElem_field0040 中,通过 if 判断得到结果。代码如下:
import bs4,requests
business_type = None
#网址更改为 POC 页面的 url
url = r’http://www.baidu.com’
wb_data = requests.get(url)
soup = bs4.BeautifulSoup(open(r’C:\Users\Lenovo\Desktop\content.do.htm’,‘rb’),‘lxml’)
'''
如果使用了 request 下载网页,就尝试用这一句
soup = bs4.BeautifulSoup(wb_data.text,‘lxml’)
'''
spanElem_field0028 = soup.select(‘#field0028_span’)[0]
spanElem_field0040 = soup.select(‘#field0040_span’)[0]
if ‘class=“ico16 examine_checkbox”’ in str(spanElem_field0028):
business_type = ‘新增’
if ‘class=“ico16 examine_checkbox”’ in str(spanElem_field0040):
business_type = ‘更改’
if business_type:
print(‘业务类型是:’,business_type)
else:
print(‘业务类型未选择,请检查确认!’)
😊 😊 😊 😊 😊 😊 😊 😊 😊 😊
欢迎指导,补充(优化)方法!!!

1. 尝试通过自定义写 css selector ,尝试失败(不知道你是否知道如何写?),用 xpath 应该可以实现。
你说的 xpath 可以实现,貌似不支持 xpath?只支持 css 吧。
不错啊,好贴,欢迎多多分享👏
现在 selector 可以用设计器内置的 selector 工具了,哈