


内网环境下破解国家外汇管理局验证码(四)
对于处理后的图片,我们运行一下 tesseract 进行识别: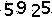
import pytesseract
from PIL import Image
print(pytesseract.image_to_string(Image.open('QlnVhCv6.png')))
运行效果如下: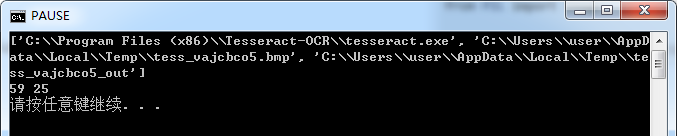
对于可能会有空格的部分直接用字符串将空格替换成空字符串即可。
另外,我之前有写过训练 tesseract 模型的方法,请看这里:Tesseract 训练自己的模型步骤
为了提高识别率,我们可以针对国家外汇管理局的验证码训练模型,这边为了节约时间直接提供训练好的语言库文件
f72025146bd0415db167a4af3ddb7c6d_yzm.rar
注意:这边只采用了四百多个样本作为训练集,想要效果更好可以自行获取更多的训练集进行训练
使用时将此文件解压后放在 Tesseract-OCR 的 tessdata 文件夹中,然后将pytesseract.image_to_string(Image.open('QlnVhCv6.png'))改为pytesseract.image_to_string(Image.open('QlnVhCv6.png'), lang='yzm')即可。
加入语言库参数之后的运行效果如下:

给你这个做个集合,内网情况下,这个用的应该不少👍