


excel 与 word 互转分享
之前 POC 的时候,遇到了 excel,word 互转的需求。分享一下我的实现方式。
数据源: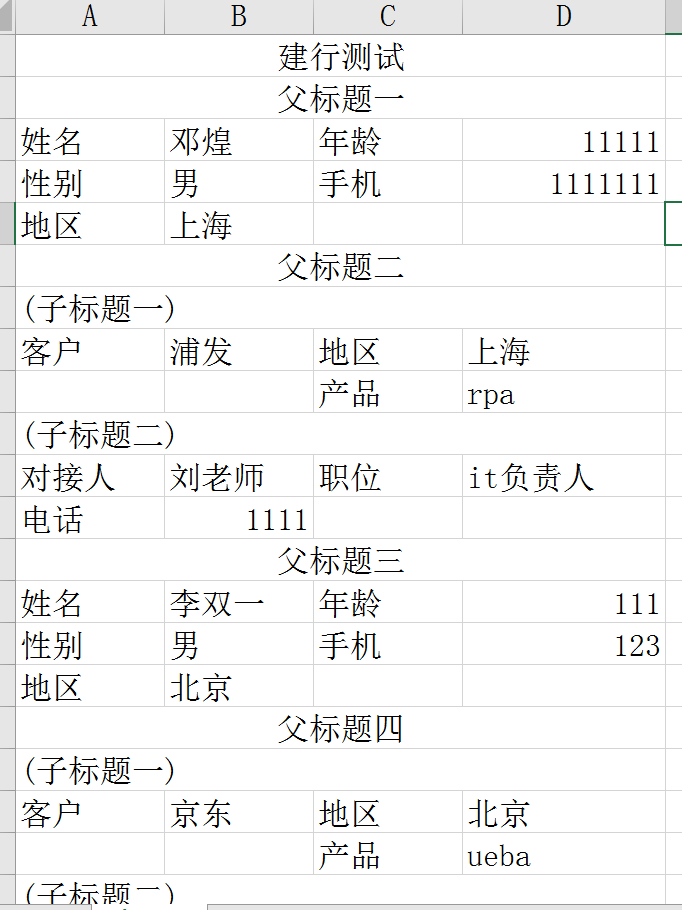
目标 word 格式:
目标 excel 格式: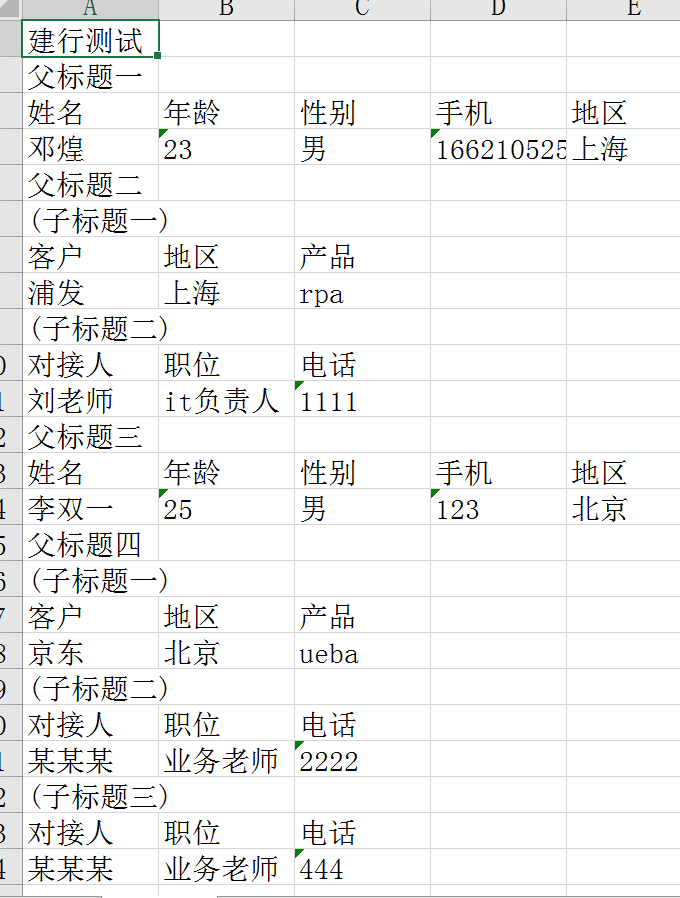
# coding=utf-8
import pandas as pd
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
def excel_to_word():
excel_path = 'C:\\isearch\\excel_sourse.xlsx'
df = pd.read_excel(excel_path,header = None)
df = df.fillna('')
df_list = df.values
document = Document()
document.add_heading(df_list[0][0],1)
document.add_heading(df_list[1][0],2)
for i in range(2,len(df_list)):
if df_list[i][1] == '' and df_list[i][2] == '' and df_list[i][3] == '' and df_list[i][0]:
if df_list[i][0].startswith('('):
document.add_heading(df_list[i][0],3)
else:
document.add_heading(df_list[i][0],2)
else:
if df_list[i][0]:
document.add_paragraph(df_list[i][0]+':'+str(df_list[i][1]))
if df_list[i][2]:
document.add_paragraph(df_list[i][2]+':'+str(df_list[i][3]))
document.save('C:\\isearch\\out_word.docx')
def word_to_excel():
df = pd.DataFrame(columns=('1', '2', '3','4','5'))
d = Document('C:\\isearch\\out_word.docx')
title_index_list = []
index_tuple_list= []
for i in range(len(d.paragraphs)):
if d.paragraphs[i].style.name != 'Normal':
title_index_list.append(i)
for i in range(len(title_index_list)-1):
if title_index_list[i+1] - title_index_list[i] !=1 :
index_tuple_list.append([title_index_list[i]+1,title_index_list[i+1]])
index_tuple_list.append([title_index_list[-1]+1,len(d.paragraphs)])
tmp_dict_list = []
for i in range(len(index_tuple_list)):
tmp_dict = {}
for j in range(index_tuple_list[i][0],index_tuple_list[i][1]):
tmp_value = d.paragraphs[j].text
tmp_list = tmp_value.split(':')
tmp_dict[tmp_list[0]] = tmp_list[1]
tmp_dict_list.append(tmp_dict)
for i in range(len(d.paragraphs)):
if d.paragraphs[i].style.name != 'Normal':
title_index_list.append(i)
tmp_dict_list_index = 0
for i in range(len(title_index_list)-1):
df.loc[len(df)] = ['' for n in range(5)]
df.iloc[-1,0] = d.paragraphs[title_index_list[i]].text
if title_index_list[i+1] - title_index_list[i] != 1 :
df.loc[len(df)] = ['' for n in range(5)]
df.loc[len(df)] = ['' for n in range(5)]
tmp_key_list = []
for key in tmp_dict_list[tmp_dict_list_index].keys():
tmp_key_list.append(key)
for i in range(len(tmp_key_list)):
df.iloc[-2,i] = tmp_key_list[i]
df.iloc[-1,i] = tmp_dict_list[tmp_dict_list_index][df.iloc[-2,i]]
tmp_dict_list_index += 1
if tmp_dict_list_index == len(tmp_dict_list):
break
df.to_excel('C:\\isearch\\out_excel.xlsx',index=False,header=None)
