


【完整版】某银行 RPA 流程开发规范 V 2.4
项目组宣言
-
我们项目组开发的流程能连续跑批 50 次不中断、不报错。
-
我们项目组不会允许同一个问题复现第二次。
-
我们项目组开发的流程“傻瓜”都能看懂。
-
我们项目组严格遵循“当日事当日毕”的原则,保质保量完成工作。
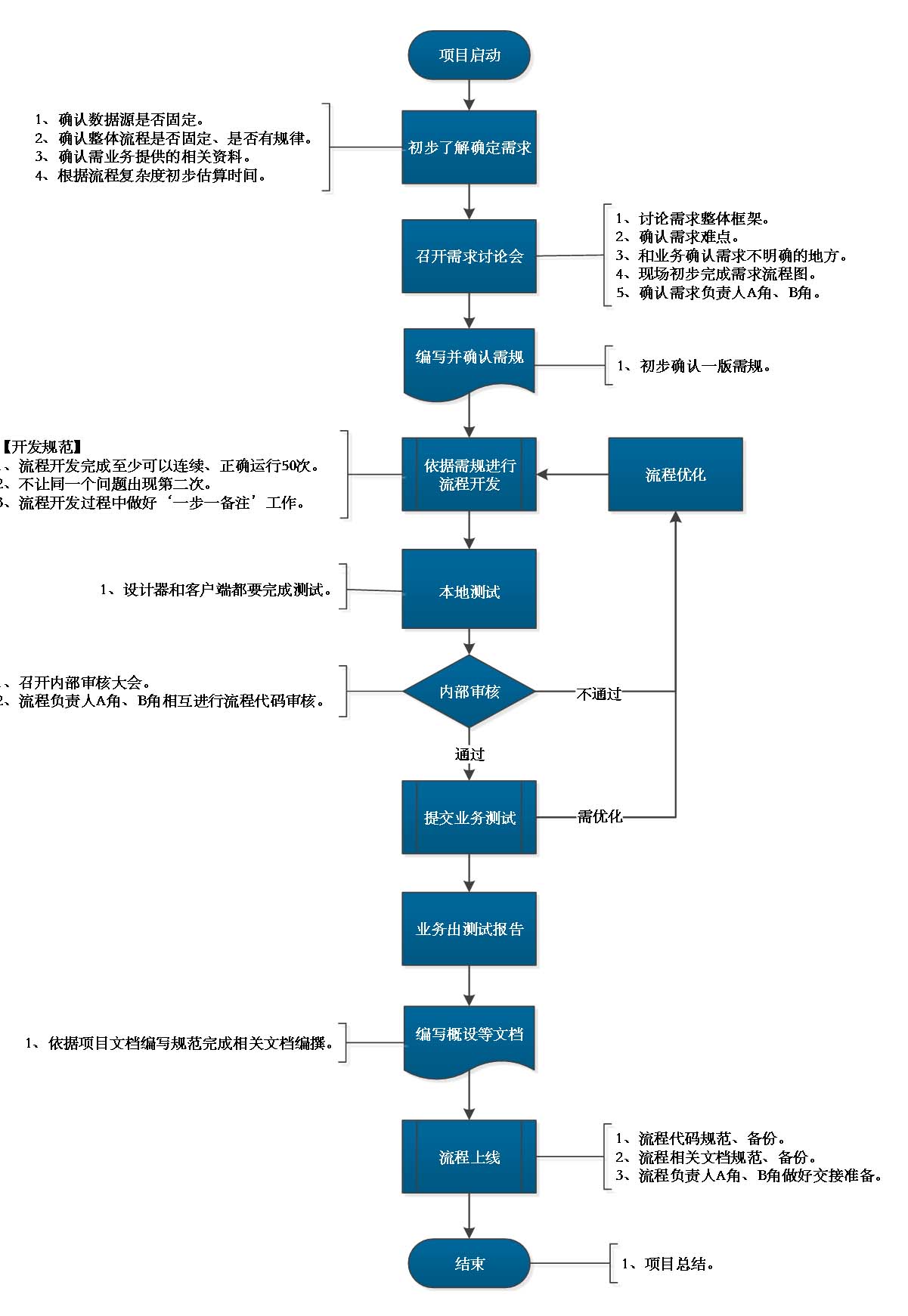
第一章 项目流程
1.1 项目开发流程图
第二章 开发规范
一个完整的 RPA 流程一定要符合这几个特性:长期稳定性、常用信息可配置性、后期扩展性、易维护性。
2.1 流程编写规范
2.1.1 变量处理规范
1、在每种代码范围内使用不同长度的规范名称:例如循环计算器用一个字符‘i’就可以了;条件和循环变量用一个单词,方法名 1-2 个单词,类名 2-3 个单词,全局变量 3-4 个单词组成,变量名尽量小写, 如有多个单词,用下划线隔开,但不能包含空格的方式。常量采用全大写。
2、为变量指定一些专门名称(可以用英文,如单词较长可以缩写),不要使用例如 “value”, “equals”, “data” 这样的变量名。
3、变量名要使用有意义的名称,通过变量名能大概反映出其具体的用途。
4、不要在变量名前加前缀,例如 o_,
obj_, m_ 之类。
5、变量名要能望文生义。(如:路径 path)
6、变量名应既简短又具有描述性。例如,name 比 n 好,student_name 比 s_n 好,name_length 比 length_of_persons_name 好。
7、慎用小写字母 l 和大写字母 O,因给他们可能被人错看成数字 1 和 0;
如: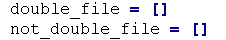
2.1.2 子流程编写规范
1、所有可以复用的变量都必须通过统一的地方控制。
2、所有公共变量最好能存储在本地的【参数表.xls】中。后期可以修改参数表来控制内部的变量。(如:用户名、密码、存储路径等)
如:

2.1.3 函数编写规范
1、所有自定义函数都要加上备注。
2、可以通用的模块,最好用函数或者子流程统一定义。(防止程序过长)
3、函数内部变量最好都要进行初始化定义。
4、流程编写完成后,删除无用的 print 语句。
5、在编写自定义函数时,先百度查一下是否有类似的库可以直接调用。(防止浪费时间)
6、函数的功能要单一,不要编写涉及多用途的函数。
如:

2.1.4 数据处理规范
1、excel 处理尽量使用 pandas 来处理。(可以减少流程运行时间)
如:
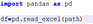
2、如必须用读单元格,且较多时,尽量放到函数中实现。(增加流程的可读性)
如:

2.1.5 控件处理规范
1、浏览器控件流程尽量少用图片识别,因浏览器大窗口和小窗口同一个图片可能会识别失败,或每次打开窗口都给窗口设置最大化。
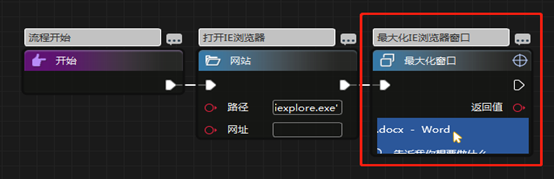
2、如某些页面可能会有缓冲,则必须等待此窗口缓冲完成后再进行下一步,不然会导致下面某个界面被影响。

3、桌面程序控件,尽量选择元素【名称】,适用 rpa5.0.0 版本。
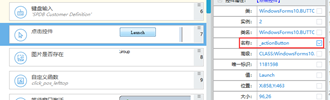
2.1.6 键盘输入处理规范
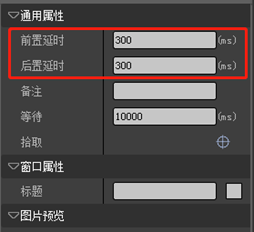
注意:所有用的键盘输入的事件必须加前后延迟(300ms)。
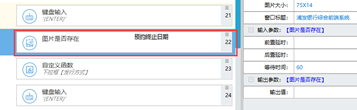
1、 如果流程中大部分都是键盘事件,因键盘事件没有报错,故切换页面和比较关键的节点最好都加上图片是否存在(rpa5.0.0)图片检测(rpa7.0.0)的等待事件。(可以大大增加流程的稳定性)
2.1.8 容错处理规范
(1)、扎堆事件容错
整理流程中可以区分出很多个小流程,比如登陆网页、打开某个界面、流程中的小分支等。这些都可以做扎堆事件容错。用 for 循环单独处理扎堆事件,如任何一步报错,重新登陆此界面。
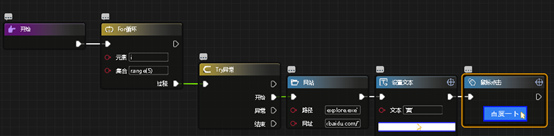
(2)、已知报错容错
已经知道此流程那些步骤会报哪种错误,单独把那些地方做容错处理。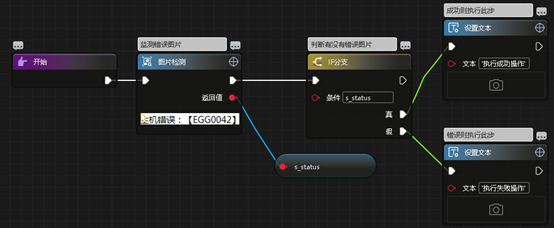
2.2 文件处理规范
2.2.1 文件夹命名规范
1、文件夹命名统一用驼峰命名方式。如:SummitInstruction
2、本地命名统一用英文命名,但不可以超过 25 个字母,可以用缩写。如:Data(数据源目录)
3、本地文件夹规范参考:

2.2.2 文件存储规范
1、不管任何途径获取到的数据源文件只能转移到历史文件夹下,不能做删除处理。(除非客户要求)。
2、流程存储在 svn 目录下,每天至少都提交一次。防止程序丢失。
3、做好版本迭代更新,方便查找管理。
4、不管流程代码还是数据文件,改动前都要做好备份。(特别是生产环境,每次改动前都需要备份)
2.3 解决问题思路
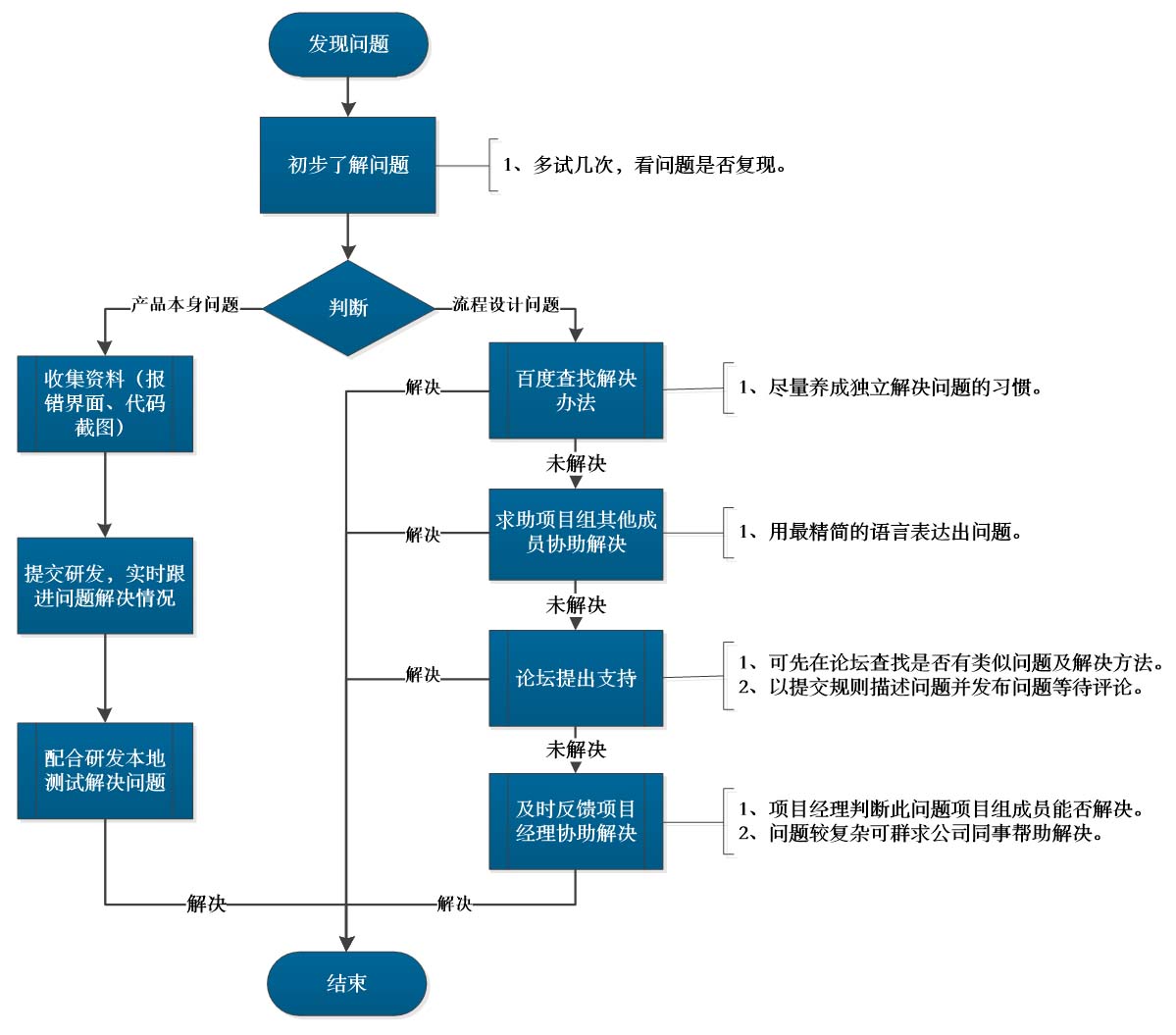
2.3.1 常见问题解决:
常见问题论坛:http://support.i-search.com.cn/article/1540084292275
2.3.2 强硬法:
直接用硬实力解决问题。
2.3.3 绕道法:
硬实力也解决不了问题的话,就让问题自己消失。
去除有问题的这步,绕过去。
第三章 可复用模块
3.1 下拉框函数
1、如果碰到 Select 选择无法设置的下拉框。
可以使用如下方式:
第一步:获取文本
第二步:与现有的数据源做对比(如果获取的文本有后面有空格或者特殊字符,则需要特殊处理一下)
第三步:如果比对成功则退出循环。
第四步:如果向下比对不成功则继续向上匹配。
第五步:如果始终都匹配不成功则超时退出。
代码如下:
def choice_drop_down_len(select_str,strlen):
try:
time.sleep(0.150)
waitfor = 10
starttime = time.time()
ud = '{DOWN}'
oldtxt = 'error'
i = 0
select_str1 = cvs_name(select_str)
iclipboard.set_clipboard(text=r'')
ikeyboard.key_send_cs(win_title=None,text=ud,waitfor=10)
time.sleep(0.100)
ikeyboard.key_send_cs(win_title=None,text=ud,waitfor=10)
while True:
txt = ''
i = i +1
#strlen = len(select_str) #记录数据源的长度
try:
for _ in range(15):
time.sleep(0.200)
ikeyboard.key_send_cs(win_title=None,text='^{c}',waitfor=10)
time.sleep(0.200)
txt=iclipboard.get_clipboard(mode=r'text')
if txt.strip() != '':
break
except Exception as e:
print (e)
print ('txt-------'+txt)
print('select_str1--------'+select_str1)
if(select_str1[:strlen].lower().strip() in txt[:strlen].lower().strip() and select_str1.strip() != '' and txt.strip() != ''): #对比数据源和获取文本得到的值
print('Choise Success:' +select_str1) #对比成功则打印成功
break
else:
runtime = time.time() - starttime #计算时间防止对比不成功导致死循环
if runtime >= 20:
raise Exception('选择超市,未选中')
time.sleep(0.02)
time.sleep(0.300)
ikeyboard.key_send_cs(win_title=None,text=ud,waitfor=10) #对比不成功则继续向此文本框发送向下键
time.sleep(0.300)
if oldtxt == txt and i > 8:
ud = '{UP}'
else:
oldtxt = txt
except Exception as e:
raise e
## 3.2 邮件函数
1、邮件回复函数
浦发这边很多流程都需要用到邮件回复功能
代码实现如下:
from ueba import
ioutlook
'''
回复邮件
'''
def
replay_on_mail(con):
''' 收邮件 '''
result =
ioutlook.recv_outlook(mail_account='黄贤淳', mail_inbox='收件箱', sender_filter=None, subject_filter=None,body_filter=None,
attachments_filter=None, only_unread=True, mark_as_read=False,
attachment_path=None, top=1)
time1 =
time.strftime("%Y-%m-%d",time.localtime())
'''回复邮件'''
result1 = result[0]
name1 = result1.Name
receiver = result1.sender_mail
subject = '答复 : ' + result1.subject
cc = result1.cc
to = result1.To
atts = result1.attachments
atts1 = ''
outlook_time =
time.strftime('%H:%M:%S',time.localtime(time.time()))
pmt_path=mkdir_parameter()
write_book(pmt_path,str2='N',n=0,con =
outlook_time)
new_body = '您好' + '\n' + con
body = new_body + '\n\n\n\n' +
'-------------------------------------------\n' +\
'发件人: ' + name1 + ';\n' + \
'发送时间: ' + result1.received_time + ';\n' + \
'收件人: ' + str(to) + ';\n' + \
'抄送人: ' + cc + ';\n' + '\n\n\n' + \
'主题: ' + subject + ';\n' + '\n\n\n' +
result1.body
ioutlook.send_outlook(receiver = receiver ,
cc = cc, subject = subject, body = body,attachments=atts1)
****
3.3 处理文件函数
文件处理是我们用的比较多的一种函数了,下面我罗列了几种:
1、 移动文件
import shutil
shutil.move(cur_dir,aft_dir)
2、 新建目录
import os
def mkdir():
# 新建目录
dir_str = 'D:/yunxing/华为'
if not os.path.exists(dir_str):
os.mkdir(dir_str)
3、 压缩目录
import shutil
def zipdir():
# 压缩目录
zip_file1 = 'D:/yunxing/'
today = datetime.datetime.now()
today_str = today.strftime('%Y%m%d')
zip_file=zip_file1 + today_str
target_dir = 'D:/yunxing/华为'
shutil.make_archive(zip_file,
'zip', target_dir)
4、 删除目录
import os
def rmdir():
# 删除目录
if os.path.exists('D:/yunxing/华为'):
shutil.rmtree('D:/yunxing/华为')
5、 删除文件
import os
def
txt_rm(myfile):
#my_file1 = 'F:/Youxun/华为/contractList.xlsx'
if os.path.exists(myfile):
os.remove(myfile)
3.4 获取时间函数
import time
time1 =
time.strftime("%Y%m%d",time.localtime())
3.5 字符半角全角转换方法
'''
半角字符转换全角字符
'''
def
strB2Q(ustring):
rstring = ''
for uchar in ustring:
inside_code = ord(uchar)
if inside_code == 32:
inside_code = 12288
elif inside_code >= 40 and
inside_code <= 41:
inside_code += 65248
rstring += chr(inside_code)
return rstring
3.6 关闭进程函数
from ubpa.iwin
import do_process_close
def
close_summit():
do_process_close('SummitFT.exe') # 把SummitFT.exe替换成想要关闭的进程名
3.7 写日志函数
'''
file_content 需要写入的日志内容
file_dir 日志存放地址
'''
def
add_logs(file_content,file_dir):
time_name =
time.strftime('%Y%m%d',time.localtime(time.time()))
file_name = str(time_name)
path = file_dir.strip()
path = path.rstrip(os.sep)
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)# 如果不存在则创建目录 #存在就往文件中写日志
file_path = open(file_dir +
file_name+'.log','a')
file_path.write(file_content)
file_path.write('\n')
file_path.close()
3.8 从字符中提取数字函数
'''把数字从字符中提取出来'''
def
get_int(str1):
to1 = re.sub('\D','',str1)
return to1
3.9 通过路径获取文件名
'''通过路径获取文件名'''
def
get_file_name(path1):
filepath,filename =
os.path.split(path1) #切割路径 filepath:文件路径 filename:文件名(有后缀)
shotname,extension =
os.path.splitext(filename) #shotname:文件名 extension:后缀
return shotname,filepath
3.10 论坛地址
论坛上有很多别人的经验,可以参考。
地址:https://support.i-search.com.cn/

好好学习
该使用 9.0 的服务器变量和服务器任务数据了,那个比存储 excel 安全太多了
好的
有空编辑一个网页版,方便大家阅读,辛苦一下
👌
很棒,期待升级到 7.0+ 的版本
继续关注和期待
一定不能烂尾,完成了我会升级为优选