

python 读取 word 文档内容学习分享
之前有小伙伴在社区中提过一个关于处理 word 文档中表格的问题,链接如下http://support.i-search.com.cn/article/1536027983339,我也是通过百度查资料进行一些学习,这里做一下自学的总结和分享。
1. 安装 python 的 docx 库
我们设计器是没有加载 docx 的库的,而读取 word 文档却需要用到这个库,因此首先你要下载库,由于 python3.x 版本移除了 exceptions 模块,但是 docx 包中引用了该模块,所以直接 pip 安装是不行的。
下载地址:python_docx-0.8.7-py2.py3-none-any.whl.zip
解压后的文件拷贝至目录C:\ueba\plugin\Com.Isearch.Func.Python\Scripts下
管理员方式运行 CMD,进入目录C:\ueba\plugin\Com.Isearch.Func.Python\Scripts
执行以下安装命令
pip install python_docx-0.8.6-py2.py3-none-any.whl

在编辑器中 import docx,不报错则说明安装成功

2. 读取 Word 文档内容
如果需要读取 word 文档中的文字,需要先了解 python-docx 模块的几个概念:
Document 对象,表示一个 word 文档。
Paragraph 对象,表示 word 文档中的一个段落
Paragraph 对象的 text 属性,表示段落中的文本内容。
我们先来看看如何调用对象,以下是 word 文档的内容: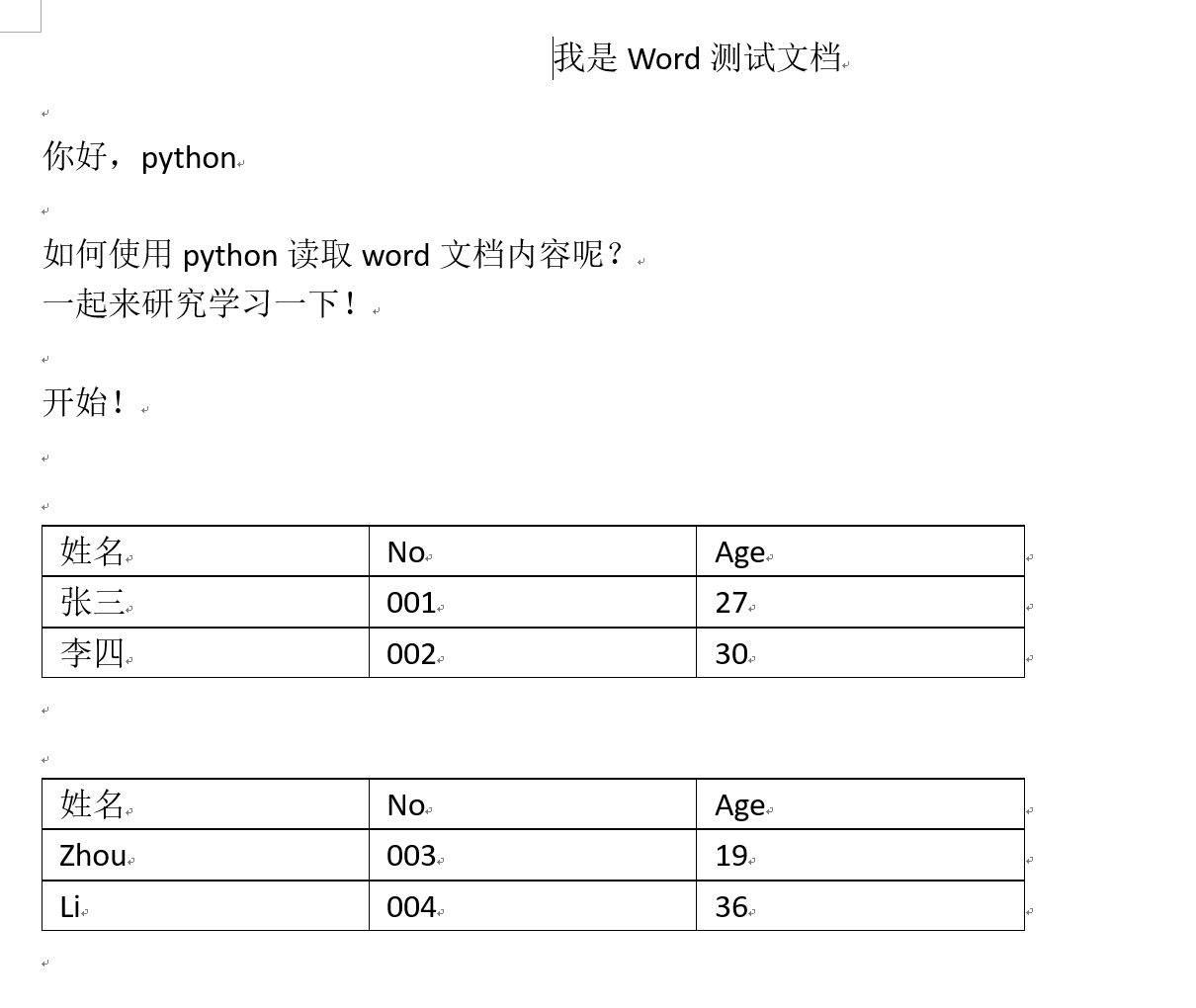
import docx
file_doc = docx.Document(r"C:\test\test.docx") #获取文档对象
print('word对象:' + str(file_doc.paragraphs)) #打印word段落的对象
print('文档段落数为:' + str(len(file_doc.paragraphs))) #获取段落数,每个回车算一个段落,空行也算,但是不包含表格行
#运行结果:
word对象:
[<docx.text.paragraph.Paragraph object at 0x035523F0>,
<docx.text.paragraph.Paragraph object at 0x035525B0>,
<docx.text.paragraph.Paragraph object at 0x03552470>,
<docx.text.paragraph.Paragraph object at 0x03552450>,
<docx.text.paragraph.Paragraph object at 0x035524B0>,
<docx.text.paragraph.Paragraph object at 0x03552530>,
<docx.text.paragraph.Paragraph object at 0x03552570>,
<docx.text.paragraph.Paragraph object at 0x03552630>,
<docx.text.paragraph.Paragraph object at 0x035525F0>,
<docx.text.paragraph.Paragraph object at 0x035524F0>,
<docx.text.paragraph.Paragraph object at 0x03552690>,
<docx.text.paragraph.Paragraph object at 0x03552610>,
<docx.text.paragraph.Paragraph object at 0x03552710>]
文档段落数为:13
根据运行的结果你会发现,文档中 13 个回车就是 13 个段落,每一个段落都是一个 Paragraph 对象,当然表格当中的回车是不算段落的。
#通过Paragraph对象,打印出每行的内容
import docx
print('打印word文档中的内容:')
for i in file_doc.paragraphs:
print(i.text) #调用paragraphs对象的text方法
tt = i.text
list.append(tt) #追加到一个数组变量中
print(‘List数据集:’ + str(list))
#运行结果:
打印word文档中的内容:
我是Word测试文档
你好,python
如何使用python读取word文档内容呢?
一起来研究学习一下!
开始!
List数据集:['我是Word测试文档', '', '你好,python', '', '如何使用python读取word文档内容呢?', '一起来研究学习一下!', '', '开始!', '', '', '', '', '']
这样就可以打印出 word 文档中的内容了,调用 Paragraph 对象的 text 方法时会默认去掉为空的行段落。
#也可以通过如下方式获取
import docx
for a in range(len(file_doc.paragraphs)):
if file_doc.paragraphs[a].text:
print('第'+str(a)+'行的内容是:'+str(file_doc.paragraphs[a].text))
else:
continue
#运行结果:
第0行的内容是:我是Word测试文档
第2行的内容是:你好,python
第4行的内容是:如何使用python读取word文档内容呢?
第5行的内容是:一起来研究学习一下!
第7行的内容是:开始!
3. 读取 Word 文档表格内容
以下是 word 文档的内容:
#我们来读取第一个表格中的数据
import docx
file_doc = docx.Document(r"C:\test\test.docx")
tables = file_doc.tables #获取文件中的表格集
print(tables) #打印表格对象,
table = tables[0] #获取文件中的第一个表格
for i in range(1,len(table.rows)): #从表格第二行开始循环读取表格数据
result = table.cell(i,0).text + ',' +table.cell(i,1).text + ',' + table.cell(i,2).text # + table.cell(i,3).text
#cell(i,0)表示第(i+1)行第1列数据,以此类推
print(result)
运行结果:
[<docx.table.Table object at 0x02ED6570>, <docx.table.Table object at 0x02ED6470>]
张三,001,27
李四,002,30
这就可以读出第一个表格的数据了
由于文档中有两个表格,因此在打印表格对象的时候会有 2 个对象[<docx.table.Table object at 0x02ED6570>, <docx.table.Table object at 0x02ED6470>]
如果需要读取第二个表格的数据,tables[0]这里下标改为1即可
好了,这是一个简单的分享,大家有更多更好的方法记得分享出来哈。

这个不错啊。厉害。