

PDF 解析实例 - 基于位置的 PDF 文本
在某个客户的具体案例里面,客户提供的一个不规则的表格要求解析,具体界面如图:
我们首先导入pdfplumber
然后我们测试了一下提取表格和提取 text:
tables = page0.extract_tables() #从page0里面取出多个tables
texts = page0.extract_text() #从page0里面取出所有文本
我们可以发现:那些表头是图片,下面那些比较清晰的印刷体是字符,其实大家用拖动选中试试就能看出哪些是字符了,由于他不是对齐的表格,提取表格也取不到任何数据,怎么办呢?
其实这个表格是固定位置的,他的任何一个打印数据应该都不会越界,我们简单的试了一下 pdfplumber 的另外一个功能,extract_words:
page0.extract_words(x_tolerance=5, y_tolerance=0)
可以看到,我们指定有 5 个单位以上的间隔,就认定是两个词了,我们得到了很多有用的信息:
{'x0': Decimal('44.884'), 'x1': Decimal('71.281'), 'top': Decimal('28.387'), 'bottom': Decimal('36.253'), 'text': '03031'},
{'x0': Decimal('87.120'), 'x1': Decimal('124.076'), 'top': Decimal('28.387'), 'bottom': Decimal('36.253'), 'text': '0012345'}
我们看到这里面是 03031 和 0012345 两个词列表,实际结果中非常多,这里不一一例举了,这里结果都返回了位置,这里面有 x0,x1,top,bottom,他们的含义是:
在程序编写中,我们配置了一个表格,用于提取我们需要的字段: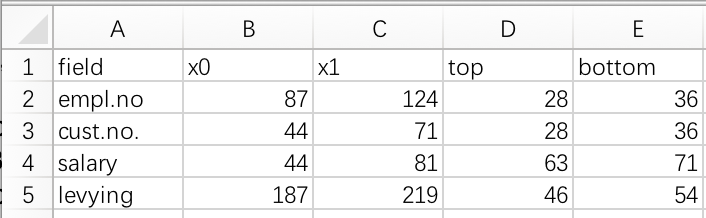
这样我们要提取更多字段,只要配置这个表格就行了
我们通过如下程序来提取这个配置:
# coding=utf-8
import pdfplumber as pp
import xlwings as xw
import pandas as pd
config_file = 'path/to/file/field_config.xlsx'
pdf_file = 'path/to/file/Payslip_Sample_IT_2.pdf'
result_file = 'path/to/file/result.xlsx'
def get_field(page, position):
rect = page.crop(position)
return rect.extract_text()
if __name__ == "__main__":
pdf = pp.open(pdf_file)
config_df = pd.read_excel(config_file)
result_df = pd.DataFrame()
for p in pdf.pages:
columns = []
data = []
for index, row in config_df.iterrows():
columns.append(row['field'])
text = get_field(p, (row['x0'], row['top'], row['x1'], row['bottom']))
data.append(text)
try:
df = pd.DataFrame([data], columns=columns)
result_df = result_df.append(df)
except Exception as e:
print('error:====', data, columns)
print(e)
result_df = result_df.reset_index(drop=True)
wb = xw.Book(result_file)
sht = wb.sheets[0]
sht.clear()
sht.range('A1').value = result_df
wb.save()
最终得到了如下结果: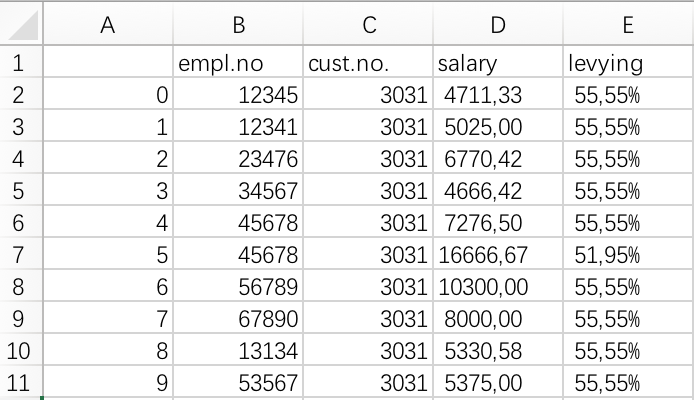
在实际操作过程中,可能会出现这种情况:
我们通过 extract_words 得到的位置是蓝色框的位置,但是实际用户需要使用的是红色框的位置,那么就需要手动调位置坐标了,所以我们需要准确理解 x0,x1,top,bottom 的含义。
如果大家有空,可以试试 pdfplumber 中的这几个函数,来准确定位:
im = p0.to_image()
rect = page.crop(position)
im.draw_rect(bbox_or_obj, fill={color}, stroke={color}
具体大家可以参考pdfplumber文档
这个由于我有个画图插件没装好,暂时还没试验成功,有心学习的可以试验一下,这里借 pdfplumber 官方的一张图来看一下效果: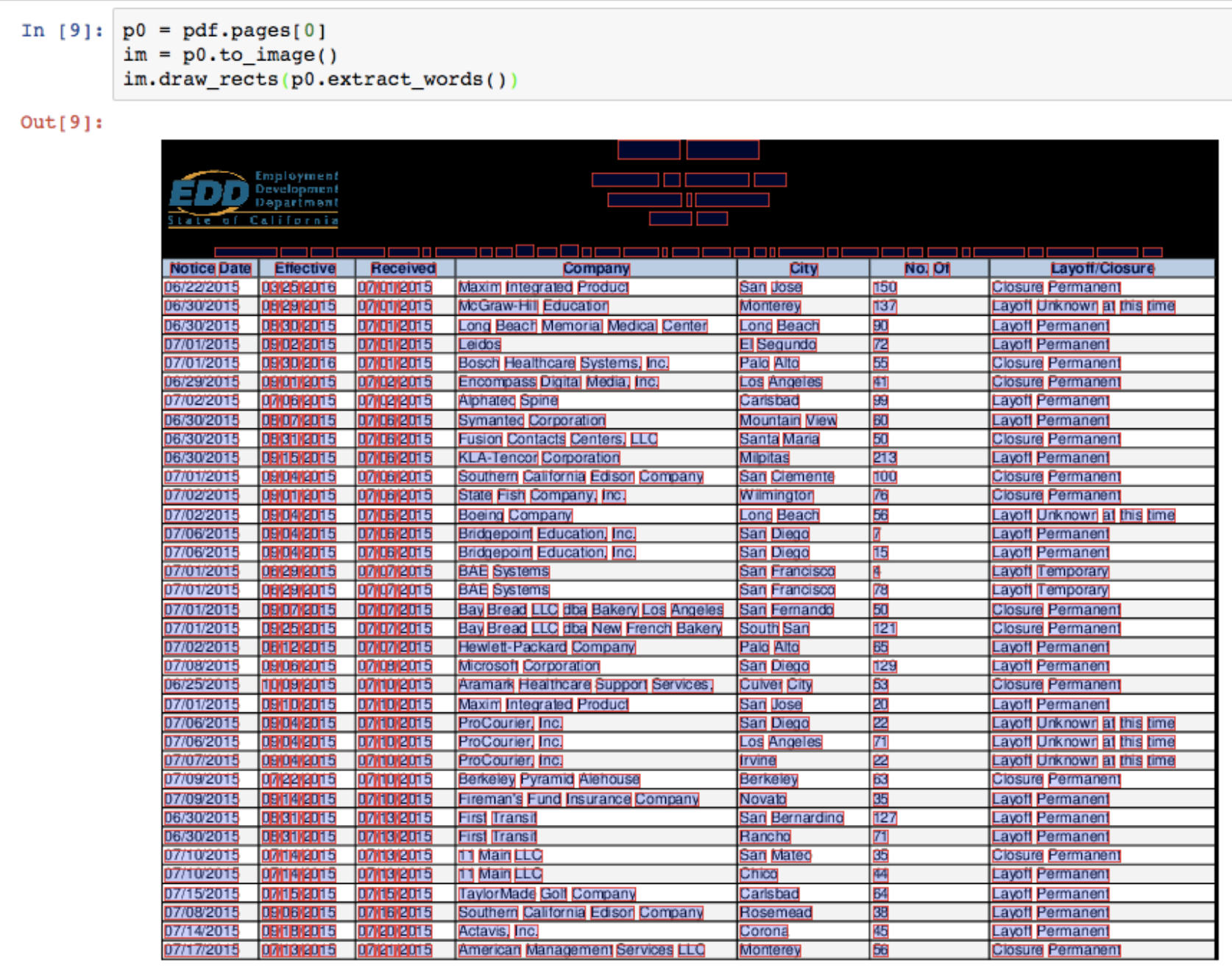
注意,他用了 extract_words 结果直接画框,我们应该逐步增大我们配置文件中框体,直到取到合适的宽度,如果大家有新的实验效果,可以跟帖在后面或者另外写一个经验

回帖内容已被屏蔽。
学习一下!
我现在才懂这个逻辑···
但这个不能通用呀··· 需要定制化配置表格,然后 crop,extract_text 转成 DataFrame。
pdfplumber 是通过文字的对齐方式,以及间距 等设置, 用以明确行和列。
这应该是 py 代码层级能做到最好的了吧···