


如何使用 python 读取 excel 日期格式
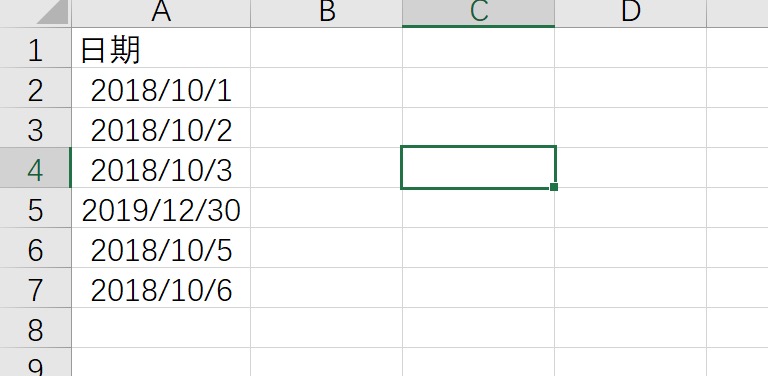
相信大家在项目中也会遇到这种问题,给的 excel 文本中会有日期,但是用平时的读取方法,读到的数据都是 float 类型,或读出来的和数据显示的不一致。读出来会如图所示: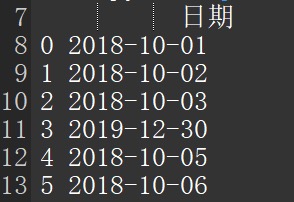
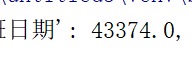
一当要读出如数据显示格式一致,直接这样读,就无法解决了。
解决代码如下:
# coding=utf-8
import xlrd
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
import traceback
from datetime import datetime
from xlrd import xldate_as_tuple
class excelHandle:
def decode(self, filename, sheetname):
try:
filename = filename.decode('utf-8')
sheetname = sheetname.decode('utf-8')
except Exception:
print(traceback.print_exc())
return filename, sheetname
def read_excel(self, filename, sheetname):
filename, sheetname = self.decode(filename, sheetname)
rbook = xlrd.open_workbook(filename)
sheet = rbook.sheet_by_name(sheetname)
rows = sheet.nrows
cols = sheet.ncols
all_content = []
for i in range(rows):
row_content = []
for j in range(cols):
ctype = sheet.cell(i, j).ctype # 表格的数据类型
cell = sheet.cell_value(i, j)
if ctype == 2 and cell % 1 == 0: # 如果是整形
cell = int(cell)
elif ctype == 3:
# 转成datetime对象
date = datetime(*xldate_as_tuple(cell, 0))
cell = date.strftime('%Y/%d/%m')
elif ctype == 4:
cell = True if cell == 1 else False
row_content.append(cell)
all_content.append(row_content)
print('[' + ','.join("'" + str(element) + "'" for element in row_content) + ']')
return all_content
if __name__ == '__main__':
eh = excelHandle()
filename = r"C:\file\账单导入模板.xlsx"
sheetname = '工作表1'
eh.read_excel(filename, sheetname)
得到的数据就会如同文件中显示的样式,如下图: 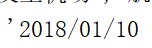

用 pandas 吧,一切都是自动的