


Hadoop - 6. 启动 Yarn
7、启动 YARN
(伪分布式不启动 YARN 也可以,一般不会影响程序执行)
有的人可能会疑惑,怎么启动 Hadoop 后,见不到书上所说的 JobTracker 和 TaskTracker,这是因为新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也称为 YARN,Yet Another Resource Negotiator)。
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性,YARN 的更多介绍在此不展开,有兴趣的可查阅相关资料。
上述通过 start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
首先修改配置文件 mapred-site.xml
cp ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml.template.txt(备份)
mv mapred-site.xml.template mapred-site.xml
然后再修改mapred-site.xml配置文件 vim mapred-site.xml
mapreduce.framework.name
yarn

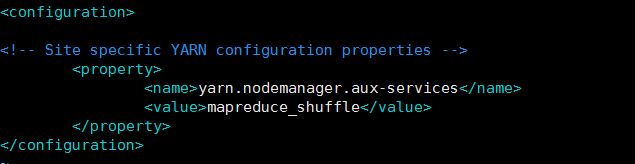
接着修改配置文件yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
然后就可以启动 YARN 了 (需要先执行过 ./sbin/satrt-dfs.sh)
./sbin/start-yarn.sh $ 启动 YARN ./sbin/mr-jobhistory-daemon**.sh**** start historyserver** # 开启历史服务器,才能在 Web 中查看任务运行情况
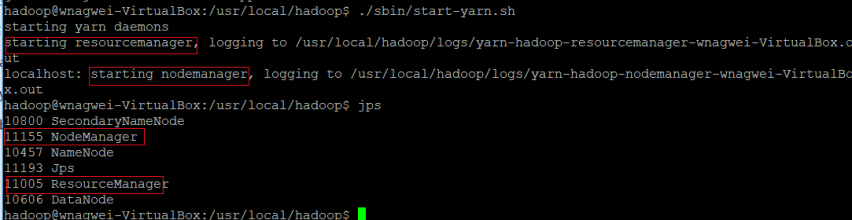
在使用 jps 查看可以看到多了几项
16707 ResourceManager
15748 DataNode
15621 NameNode
15911 SecondaryNameNode
16811 NodeManager
17199 Jps
17151 JobHistoryServer
启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式,任务调度不同。观察日志信息可以发现,不启用 YARN 时,是”mapred.LocalJobRunner”在跑任务,启用 YARN 之后,是”mapred.YARNRunner”在跑任务。启动 YARN 有个好处是可以通过 web 界面查看任务的运行情况。
但 YARN 主要是为集群提供更好的资源管理和任务调度,然而这在单机上体现不出价值,反而会使程序跑的稍慢些。因此在单机上是否开启 YARN 就看实际情况了。
如果不想启动 YARN,务必把配置文件mapred-site.xml重命名,改成mapred-site.xml.template, 需要时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示”Retrying connect to server:0.0.0.0/0.0.0.0:8032”的错误,这也是为何该配置文件初始文件名为 mapred-site.xml.template
成功启动后,可以访问 Web 界面 http://[ip,fqdn]:/50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
同样的,关闭 YARN 的脚本如下:
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
