


如何将大的 Excel 无损拆分成若干个小文件
前段时间有个同事在项目中遇到一个问题,需求中有一个是将 Excel 文件传入系统,但是上传过程中,发现文件太大,无法上传。因而需要将该大文件拆分成若干个小文件,在上传。
代码如下:
# coding=utf-8
import os
import pandas as pd
import math
def file_split(filename, file_num, header=True):
# 根据是否有表头执行不同程序,默认是否表头的
if header:
# 获得每个文件需要有的行数
chunksize = 1000000 # 先初始化的chunksize是100W
data1 = pd.read_csv(open(filename), chunksize=chunksize, sep=',', encoding='utf-8')
num = 0
for chunk in data1:
num += len(chunk)
chunksize = round(num / file_num + 1)
# 需要存的file
head, tail = os.path.splitext(filename)
data2 = pd.read_csv(open(filename), chunksize=chunksize, sep=',', encoding='utf-8')
i = 0 # 定文件名
for chunk in data2:
chunk.to_csv('{0}_{1}{2}'.format(head, i, tail), header=None, index=False)
print('保存第{0}个数据'.format(i))
i += 1
else:
# 获得每个文件需要有的行数
chunksize = 1000000 # 先初始化的chunksize是100W
data1 = pd.read_csv(open(filename), chunksize=chunksize, header=None, sep=',')
num = 0
for chunk in data1:
num += len(chunk)
chunksize = round(num / file_num + 1)
# 需要存的file
head, tail = os.path.splitext(filename)
data2 = pd.read_csv(open(filename), chunksize=chunksize, header=None, sep=',')
i = 0 # 定文件名
for chunk in data2:
chunk.to_csv('{0}_{1}{2}'.format(head, i, tail), header=None, index=False)
print('保存第{0}个数据'.format(i))
i += 1
if __name__ == '__main__':
rootdir = "C:/file/wu"
for parent, dirnames, filenames in os.walk(rootdir): # 三个参数:分别返回1.父目录 2.所有文件夹名字(不含路径) 3.所有文件名字
for filename in filenames: # 输出文件信息
file = os.path.join(parent, filename).replace('\\', '/') # 输出文件路径信息
print("文件名为:",filename)
size = os.path.getsize(file) # 读取文件的大小,单位为B
mb_size = float(size)/(1024*1024) # 转化单位为MB
print("文件大小为{}MB".format(mb_size))
time = math.ceil(mb_size/100) # 拆分文件的次数,以100MB为每个文件的大小
print("按照每份文件大小100MB,分成{}份".format(time))
file_split(filename=file, file_num=time, header=False)
代码中解决一个大文件夹下,读取每个子文件夹下所有文件,并以每个小文件大小为 100MB 去拆分。先获取文件的大小,与 100 相除并向上取整,得到需拆分的个数,然后进行无损拆分。实际中可根据需求更改。
执行结果如下: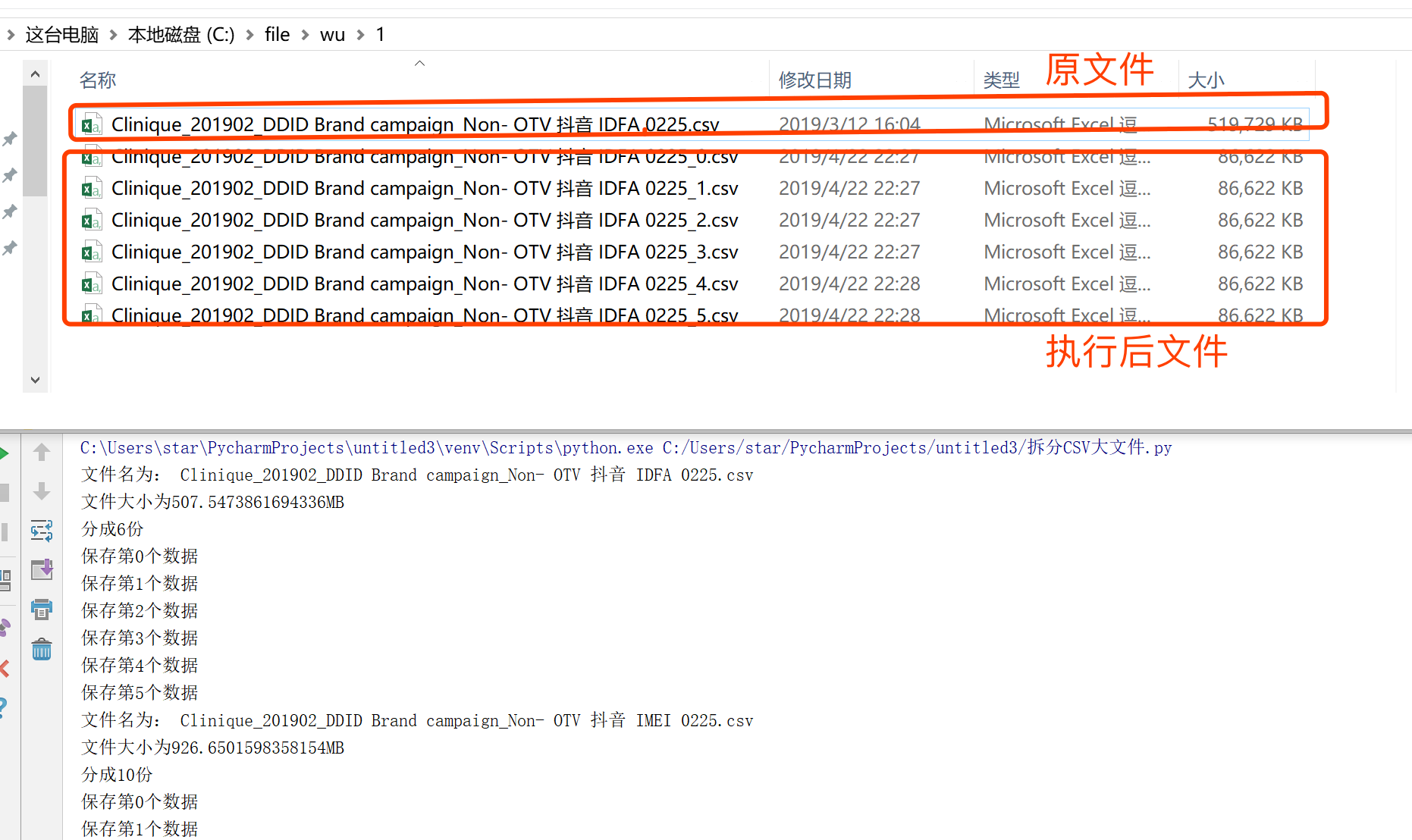

可以, 👍