

内置 OCR 识别引擎 Tesseract 通过白名单提高识别率的方法
大家都知道我们的设计器内置了 OCR 识别引擎 Tesseract
http://support.i-search.com.cn/article/1531145346828
但是我们只能保证他的识别,却不能保证准确性,下面给大家介绍一个可以提高识别率的方法。(适用于部分场景提高识别率)
场景:
我们要识别下图信息
我们使用设计器内置 OCR 识别器 Tesseract 通过以下代码拾取结果如下
import pytesseract
from PIL import Image
image=Image.open("E:/艺赛旗/ceshi.png")
ocr_code = pytesseract.image_to_string(image, 'chi_sim').replace(' ', '')
print(ocr_code)
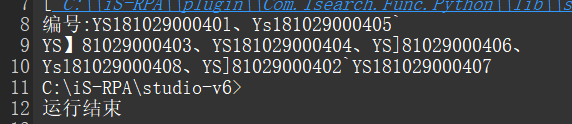
我们可以看到,YS 的大小写没有区分开来,并且部分数字 1 识别成了】或者 ],这样误差会影响后续的数据处理。
根据需求了解,这里的数据均是 YS+ 数字的组合,所以我们可以尝试添加白名单,使 Tesseract 只匹配 YS 以及数字。
首先我们进入 C:\iS-RPA\plugin\Com.Isearch.Tesseract\tessdata 目录。
在该目录下新建一个 configs 的文件夹
然后将 digits.7z 文件解压后放入该目录。当然也可以自己新建一个白名单,只要填入 tessedit_char_whitelist+ 内容即可。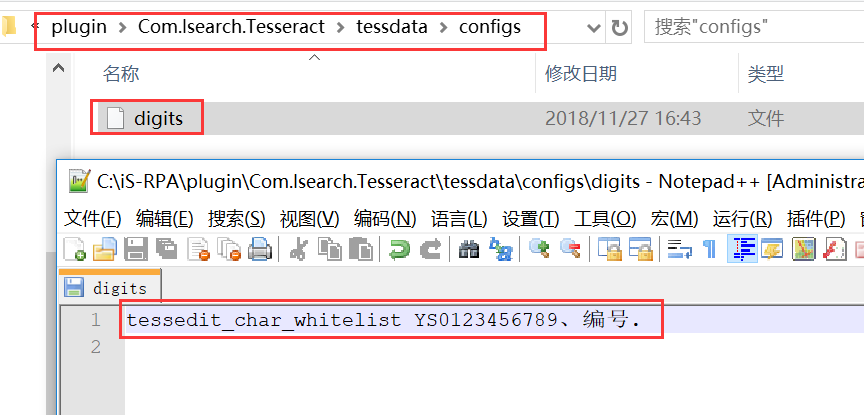
打开目录我们发现里面的内容其实就是白名单,我们将需要识别的相关字符填入,这里识别编号 +YS+ 数字,所以我们修改的内容为 YS0123456789、编号.
然后我们需要修改一下代码如下,给 imagetostring 的方法添加两个参数:
import pytesseract
from PIL import Image
image=Image.open("E:/艺赛旗/ceshi.png")
ocr_code = pytesseract.imagetostring(image, 'chisim',False,'digits').replace(' ', '')
print(ocr_code)
然后我们在设计器执行一下,如下图:
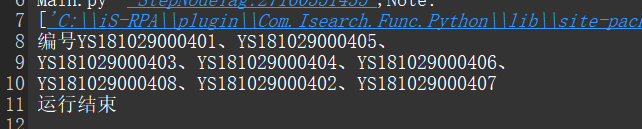
可以看到所有的数据均正确的识别出来,没有大小写以及】、] 的干扰了。这样的数据就准确多了。
当然我们也可以通过白名单的方法对需要拾取得到数据进行筛选,比如这里我们不需要 ‘编号’ 两个字只需要 YS+ 数字,我们将白名单 digits 中的 ‘编号’ 两字剔除。
运行一下,就可以看到 ‘编号’ 两字被剔除出去了,只剩下我们需要的 YS+ 数字。
在遇到一些合适的 OCR 场景,大家可以尝试使用以上白名单的方法,提高 Tesseract 的识别率。

优秀
戴老板优秀